Existing autonomous research agents can support parts of the research process, but most systems still treat research as either an isolated assistant task or a closed workflow. Therefore, autonomous science needs a collaboration infrastructure that coordinates projects, agents, and digital and physical resources. We identify this as a shift from code-centered execution loops to research-oriented collaboration processes, where questions, eviden...
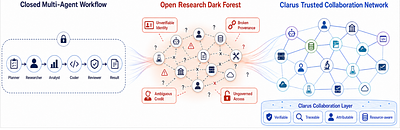
moreExisting autonomous research agents can support parts of the research process, but most systems still treat research as either an isolated assistant task or a closed workflow. Therefore, autonomous science needs a collaboration infrastructure that coordinates projects, agents, and digital and physical resources. We identify this as a shift from code-centered execution loops to research-oriented collaboration processes, where questions, evidence, participants, and resources must be coordinated under uncertainty. In this framing, an agent may be an AI system, a human researcher, a team, a laboratory, or an organization-backed participant. To this end, we present Clarus, a collaboration infrastructure for coordinating autonomous research agents toward web-scale scientific collaboration. Clarus reformulates research as an open, auditable, attributable, and resource-aware multi-phase collaboration process. It defines a minimal project-agent-resource object model and organizes scientific collaboration through four layers including Research Application, Digital Collaboration, Physical Substrate, and Physical World. Core modules are implemented as pluggable mechanisms, allowing Clarus to adapt to task risk, collaboration structure, and resource constraints. Through a controlled paper-generation case study, we show that Clarus can organize a research goal into a traceable, reviewable, attributable, and accumulative collaboration network across phases, tasks, and participants. Together, the object model, collaboration protocol, trust mechanisms, and prototype validation provide an initial foundation for open research networks. Clarus is now available at clarus.holosai.io.
less