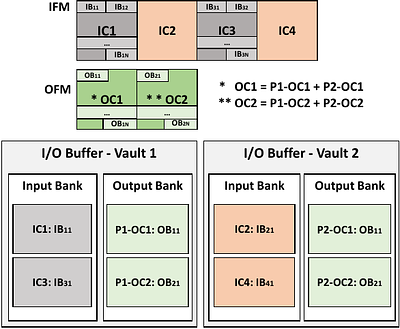
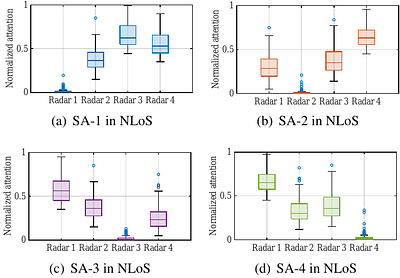
Radar-based techniques for detecting vital signs have shown promise for continuous contactless vital sign sensing and healthcare applications. However, real-world indoor environments face significant challenges for existing vital sign monitoring systems. These include signal blockage in non-line-of-sight (NLOS) situations, movement of human subjects, and alterations in location and orientation. Additionally, these existing systems failed to...
more Radar-based techniques for detecting vital signs have shown promise for continuous contactless vital sign sensing and healthcare applications. However, real-world indoor environments face significant challenges for existing vital sign monitoring systems. These include signal blockage in non-line-of-sight (NLOS) situations, movement of human subjects, and alterations in location and orientation. Additionally, these existing systems failed to address the challenge of tracking multiple targets simultaneously. To overcome these challenges, we present MEDUSA, a novel coherent ultra-wideband (UWB) based distributed multiple-input multiple-output (MIMO) radar system, especially it allows users to customize and disperse the $16 \times 16$ into sub-arrays. MEDUSA takes advantage of the diversity benefits of distributed yet wirelessly synchronized MIMO arrays to enable robust vital sign monitoring in real-world and daily living environments where human targets are moving and surrounded by obstacles. We've developed a scalable, self-supervised contrastive learning model which integrates seamlessly with our hardware platform. Each attention weight within the model corresponds to a specific antenna pair of Tx and Rx. The model proficiently recovers accurate vital sign waveforms by decomposing and correlating the mixed received signals, including comprising human motion, mobility, noise, and vital signs. Through extensive evaluations involving 21 participants and over 200 hours of collected data (3.75 TB in total, with 1.89 TB for static subjects and 1.86 TB for moving subjects), MEDUSA's performance has been validated, showing an average gain of 20% compared to existing systems employing COTS radar sensors. This demonstrates MEDUSA's spatial diversity gain for real-world vital sign monitoring, encompassing target and environmental dynamics in familiar and unfamiliar indoor environments.
less