Large language models (LLMs) are increasingly used to take actions in the real world and support human decision-making, yet most agents rely on parametric knowledge, fixed post-training data, retrieval, or search. This paradigm breaks down in novel domains and for sophisticated queries that cannot be answered from prior knowledge alone. Knowing the laws of physics, for instance, does not by itself enable LLMs to answer queries or complete lon...
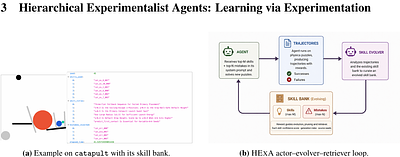
moreLarge language models (LLMs) are increasingly used to take actions in the real world and support human decision-making, yet most agents rely on parametric knowledge, fixed post-training data, retrieval, or search. This paradigm breaks down in novel domains and for sophisticated queries that cannot be answered from prior knowledge alone. Knowing the laws of physics, for instance, does not by itself enable LLMs to answer queries or complete long-horizon tasks in a complex physical system. To address this, we introduce Hierarchical Experimentalist Agents (HExA), an in-context self-improvement framework to learn from active experimentation. HExA iteratively designs and refines query-relevant experiments, learns a reusable library of composable skills from experience, and integrates experimental evidence to answer queries or take actions. HExA is training-free, compatible with any black-box model, and does not require external supervision, oracles, or offline data. To evaluate active experimentation, we introduce Interphyre, a tool-calling benchmark built on the PHYRE 2D procedural physics environment, where agents propose interventions and test hypotheses through simulation APIs. Experiments show that current LLM agents struggle in these settings, especially on the hardest levels of Interphyre. Claude Sonnet 4.6 achieves only 2% success, while HExA improves the same model to up to 77% success. HExA also improves open-weight models and outperforms agentic baselines such as ReAct and Reflexion. Moreover, using only skills learned from easier levels and transferred without active experimentation, HExA achieves 44% success, demonstrating the reusability and generalization of its learned skills. Overall, HExA shows that learning through active experimentation can help agents discover useful knowledge, acquire reusable skills, and make efficient progress on novel long-horizon tasks.
less