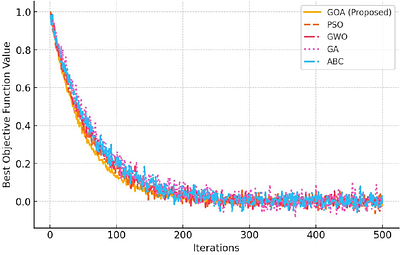
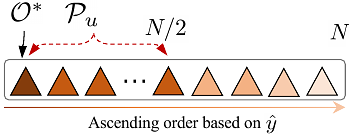
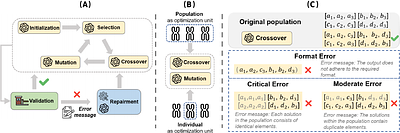
This paper presents the Goat Optimization Algorithm (GOA), a novel bio-inspired metaheuristic optimization technique inspired by goats' adaptive foraging, strategic movement, and parasite avoidance behaviors.GOA is designed to balance exploration and exploitation effectively by incorporating three key mechanisms, adaptive foraging for global search, movement toward the best solution for local refinement, and a jump strategy to escape local ...
more This paper presents the Goat Optimization Algorithm (GOA), a novel bio-inspired metaheuristic optimization technique inspired by goats' adaptive foraging, strategic movement, and parasite avoidance behaviors.GOA is designed to balance exploration and exploitation effectively by incorporating three key mechanisms, adaptive foraging for global search, movement toward the best solution for local refinement, and a jump strategy to escape local optima.A solution filtering mechanism is introduced to enhance robustness and maintain population diversity. The algorithm's performance is evaluated on standard unimodal and multimodal benchmark functions, demonstrating significant improvements over existing metaheuristics, including Particle Swarm Optimization (PSO), Grey Wolf Optimizer (GWO), Genetic Algorithm (GA), Whale Optimization Algorithm (WOA), and Artificial Bee Colony (ABC). Comparative analysis highlights GOA's superior convergence rate, enhanced global search capability, and higher solution accuracy.A Wilcoxon rank-sum test confirms the statistical significance of GOA's exceptional performance. Despite its efficiency, computational complexity and parameter sensitivity remain areas for further optimization. Future research will focus on adaptive parameter tuning, hybridization with other metaheuristics, and real-world applications in supply chain management, bioinformatics, and energy optimization. The findings suggest that GOA is a promising advancement in bio-inspired optimization techniques.
less