By: Tamay Aykut, Markus Hofbauer, Christopher Kuhn, Eckehard Steinbach, Bernd Girod
The COVID-19 pandemic shifted many events in our daily lives into the virtual domain. While virtual conference systems provide an alternative to physical meetings, larger events require a muted audience to avoid an accumulation of background noise and distorted audio. However, performing artists strongly rely on the feedback of their audience. We propose a concept for a virtual audience framework which supports all participants with the amb... more
The COVID-19 pandemic shifted many events in our daily lives into the virtual domain. While virtual conference systems provide an alternative to physical meetings, larger events require a muted audience to avoid an accumulation of background noise and distorted audio. However, performing artists strongly rely on the feedback of their audience. We propose a concept for a virtual audience framework which supports all participants with the ambience of a real audience. Audience feedback is collected locally, allowing users to express enthusiasm or discontent by selecting means such as clapping, whistling, booing, and laughter. This feedback is sent as abstract information to a virtual audience server. We broadcast the combined virtual audience feedback information to all participants, which can be synthesized as a single acoustic feedback by the client. The synthesis can be done by turning the collective audience feedback into a prompt that is fed to state-of-the-art models such as AudioGen. This way, each user hears a single acoustic feedback sound of the entire virtual event, without requiring to unmute or risk hearing distorted, unsynchronized feedback. less
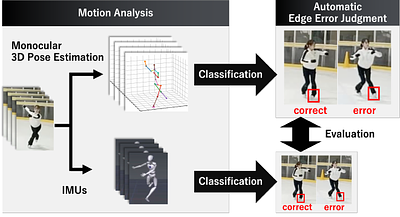
By: Ryota Tanaka, Tomohiro Suzuki, Kazuya Takeda, Keisuke Fujii
Automatic evaluating systems are fundamental issues in sports technologies. In many sports, such as figure skating, automated evaluating methods based on pose estimation have been proposed. However, previous studies have evaluated skaters' skills in 2D analysis. In this paper, we propose an automatic edge error judgment system with a monocular smartphone camera and inertial sensors, which enable us to analyze 3D motions. Edge error is one o... more
Automatic evaluating systems are fundamental issues in sports technologies. In many sports, such as figure skating, automated evaluating methods based on pose estimation have been proposed. However, previous studies have evaluated skaters' skills in 2D analysis. In this paper, we propose an automatic edge error judgment system with a monocular smartphone camera and inertial sensors, which enable us to analyze 3D motions. Edge error is one of the most significant scoring items and is challenging to automatically judge due to its 3D motion. The results show that the model using 3D joint position coordinates estimated from the monocular camera as the input feature had the highest accuracy at 83% for unknown skaters' data. We also analyzed the detailed motion analysis for edge error judgment. These results indicate that the monocular camera can be used to judge edge errors automatically. We will provide the figure skating single Lutz jump dataset, including pre-processed videos and labels, at https://github.com/ryota-takedalab/JudgeAI-LutzEdge. less

By: Jinzheng Zhao, Yong Xu, Xinyuan Qian, Davide Berghi, Peipei Wu, Meng Cui, Jianyuan Sun, Philip J. B. Jackson, Wenwu Wang
Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual ... more
Audio-visual speaker tracking has drawn increasing attention over the past few years due to its academic values and wide application. Audio and visual modalities can provide complementary information for localization and tracking. With audio and visual information, the Bayesian-based filter can solve the problem of data association, audio-visual fusion and track management. In this paper, we conduct a comprehensive overview of audio-visual speaker tracking. To our knowledge, this is the first extensive survey over the past five years. We introduce the family of Bayesian filters and summarize the methods for obtaining audio-visual measurements. In addition, the existing trackers and their performance on AV16.3 dataset are summarized. In the past few years, deep learning techniques have thrived, which also boosts the development of audio visual speaker tracking. The influence of deep learning techniques in terms of measurement extraction and state estimation is also discussed. At last, we discuss the connections between audio-visual speaker tracking and other areas such as speech separation and distributed speaker tracking. less
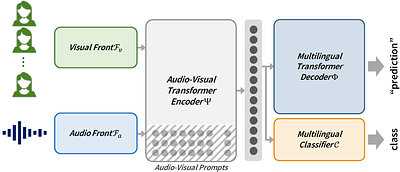
By: Joanna Hong, Se Jin Park, Yong Man Ro
We present a novel approach to multilingual audio-visual speech recognition tasks by introducing a single model on a multilingual dataset. Motivated by a human cognitive system where humans can intuitively distinguish different languages without any conscious effort or guidance, we propose a model that can capture which language is given as an input speech by distinguishing the inherent similarities and differences between languages. To do ... more
We present a novel approach to multilingual audio-visual speech recognition tasks by introducing a single model on a multilingual dataset. Motivated by a human cognitive system where humans can intuitively distinguish different languages without any conscious effort or guidance, we propose a model that can capture which language is given as an input speech by distinguishing the inherent similarities and differences between languages. To do so, we design a prompt fine-tuning technique into the largely pre-trained audio-visual representation model so that the network can recognize the language class as well as the speech with the corresponding language. Our work contributes to developing robust and efficient multilingual audio-visual speech recognition systems, reducing the need for language-specific models. less
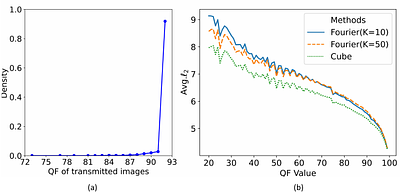
By: Jun Liu, Jiantao Zhou, Haiwei Wu, Weiwei Sun, Jinyu Tian
Online Social Networks (OSNs) have blossomed into prevailing transmission channels for images in the modern era. Adversarial examples (AEs) deliberately designed to mislead deep neural networks (DNNs) are found to be fragile against the inevitable lossy operations conducted by OSNs. As a result, the AEs would lose their attack capabilities after being transmitted over OSNs. In this work, we aim to design a new framework for generating robus... more
Online Social Networks (OSNs) have blossomed into prevailing transmission channels for images in the modern era. Adversarial examples (AEs) deliberately designed to mislead deep neural networks (DNNs) are found to be fragile against the inevitable lossy operations conducted by OSNs. As a result, the AEs would lose their attack capabilities after being transmitted over OSNs. In this work, we aim to design a new framework for generating robust AEs that can survive the OSN transmission; namely, the AEs before and after the OSN transmission both possess strong attack capabilities. To this end, we first propose a differentiable network termed SImulated OSN (SIO) to simulate the various operations conducted by an OSN. Specifically, the SIO network consists of two modules: 1) a differentiable JPEG layer for approximating the ubiquitous JPEG compression and 2) an encoder-decoder subnetwork for mimicking the remaining operations. Based upon the SIO network, we then formulate an optimization framework to generate robust AEs by enforcing model outputs with and without passing through the SIO to be both misled. Extensive experiments conducted over Facebook, WeChat and QQ demonstrate that our attack methods produce more robust AEs than existing approaches, especially under small distortion constraints; the performance gain in terms of Attack Success Rate (ASR) could be more than 60%. Furthermore, we build a public dataset containing more than 10,000 pairs of AEs processed by Facebook, WeChat or QQ, facilitating future research in the robust AEs generation. The dataset and code are available at https://github.com/csjunjun/RobustOSNAttack.git. less
By: Sheng Zhou, Dan Guo, Jia Li, Xun Yang, Meng Wang
Text-based visual question answering (TextVQA) faces the significant challenge of avoiding redundant relational inference. To be specific, a large number of detected objects and optical character recognition (OCR) tokens result in rich visual relationships. Existing works take all visual relationships into account for answer prediction. However, there are three observations: (1) a single subject in the images can be easily detected as multi... more
Text-based visual question answering (TextVQA) faces the significant challenge of avoiding redundant relational inference. To be specific, a large number of detected objects and optical character recognition (OCR) tokens result in rich visual relationships. Existing works take all visual relationships into account for answer prediction. However, there are three observations: (1) a single subject in the images can be easily detected as multiple objects with distinct bounding boxes (considered repetitive objects). The associations between these repetitive objects are superfluous for answer reasoning; (2) two spatially distant OCR tokens detected in the image frequently have weak semantic dependencies for answer reasoning; and (3) the co-existence of nearby objects and tokens may be indicative of important visual cues for predicting answers. Rather than utilizing all of them for answer prediction, we make an effort to identify the most important connections or eliminate redundant ones. We propose a sparse spatial graph network (SSGN) that introduces a spatially aware relation pruning technique to this task. As spatial factors for relation measurement, we employ spatial distance, geometric dimension, overlap area, and DIoU for spatially aware pruning. We consider three visual relationships for graph learning: object-object, OCR-OCR tokens, and object-OCR token relationships. SSGN is a progressive graph learning architecture that verifies the pivotal relations in the correlated object-token sparse graph, and then in the respective object-based sparse graph and token-based sparse graph. Experiment results on TextVQA and ST-VQA datasets demonstrate that SSGN achieves promising performances. And some visualization results further demonstrate the interpretability of our method. less
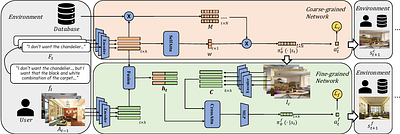
Interactive Interior Design Recommendation via Coarse-to-fine Multimodal Reinforcement Learning
0upvotes
By: He Zhang, Ying Sun, Weiyu Guo, Yafei Liu, Haonan Lu, Xiaodong Lin, Hui Xiong
Personalized interior decoration design often incurs high labor costs. Recent efforts in developing intelligent interior design systems have focused on generating textual requirement-based decoration designs while neglecting the problem of how to mine homeowner's hidden preferences and choose the proper initial design. To fill this gap, we propose an Interactive Interior Design Recommendation System (IIDRS) based on reinforcement learning (... more
Personalized interior decoration design often incurs high labor costs. Recent efforts in developing intelligent interior design systems have focused on generating textual requirement-based decoration designs while neglecting the problem of how to mine homeowner's hidden preferences and choose the proper initial design. To fill this gap, we propose an Interactive Interior Design Recommendation System (IIDRS) based on reinforcement learning (RL). IIDRS aims to find an ideal plan by interacting with the user, who provides feedback on the gap between the recommended plan and their ideal one. To improve decision-making efficiency and effectiveness in large decoration spaces, we propose a Decoration Recommendation Coarse-to-Fine Policy Network (DecorRCFN). Additionally, to enhance generalization in online scenarios, we propose an object-aware feedback generation method that augments model training with diversified and dynamic textual feedback. Extensive experiments on a real-world dataset demonstrate our method outperforms traditional methods by a large margin in terms of recommendation accuracy. Further user studies demonstrate that our method reaches higher real-world user satisfaction than baseline methods. less
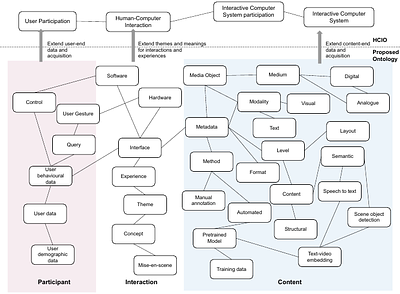
By: Yuchen Yang
Situated in the intersection of audiovisual archives, computational methods, and immersive interactions, this work probes the increasingly important accessibility issues from a two-fold approach. Firstly, the work proposes an ontological data model to handle complex descriptors (metadata, feature vectors, etc.) with regard to user interactions. Secondly, this work examines text-to-video retrieval from an implementation perspective by propos... more
Situated in the intersection of audiovisual archives, computational methods, and immersive interactions, this work probes the increasingly important accessibility issues from a two-fold approach. Firstly, the work proposes an ontological data model to handle complex descriptors (metadata, feature vectors, etc.) with regard to user interactions. Secondly, this work examines text-to-video retrieval from an implementation perspective by proposing a classifier-enhanced workflow to deal with complex and hybrid queries and a training data augmentation workflow to improve performance. This work serves as the foundation for experimenting with novel public-facing access models to large audiovisual archives less
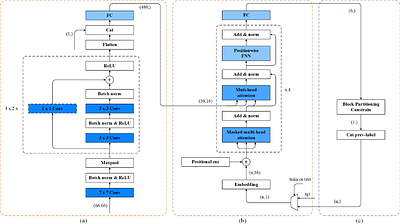
By: Yucheng Jiang, Han Peng, Yan Song, Jie Yu, Peng Zhang, Songping Mai
The recursive intra-frame block partitioning decision process, a crucial component of the next-generation video coding standards, exerts significant influence over the encoding time. In this paper, we propose an encoder-decoder neural network (NN) to accelerate this process. Specifically, a CNN is utilized to compress the pixel data of the largest coding unit (LCU) into a fixed-length vector. Subsequently, a Transformer decoder is employed ... more
The recursive intra-frame block partitioning decision process, a crucial component of the next-generation video coding standards, exerts significant influence over the encoding time. In this paper, we propose an encoder-decoder neural network (NN) to accelerate this process. Specifically, a CNN is utilized to compress the pixel data of the largest coding unit (LCU) into a fixed-length vector. Subsequently, a Transformer decoder is employed to transcribe the fixed-length vector into a variable-length vector, which represents the block partitioning outcomes of the encoding LCU. The vector transcription process adheres to the constraints imposed by the block partitioning algorithm. By fully parallelizing the NN prediction in the intra-mode decision, substantial time savings can be attained during the decision phase. The experimental results obtained from high-definition (HD) sequences coding demonstrate that this framework achieves a remarkable 87.84\% reduction in encoding time, with a relatively small loss (8.09\%) of coding performance compared to AVS3 HPM4.0. less
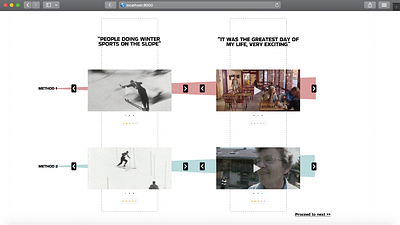
By: Yuchen Yang
Audiovisual (AV) archives, as an essential reservoir of our cultural assets, are suffering from the issue of accessibility. The complex nature of the medium itself made processing and interaction an open challenge still in the field of computer vision, multimodal learning, and human-computer interaction, as well as in culture and heritage. In recent years, with the raising of video retrieval tasks, methods in retrieving video content with n... more
Audiovisual (AV) archives, as an essential reservoir of our cultural assets, are suffering from the issue of accessibility. The complex nature of the medium itself made processing and interaction an open challenge still in the field of computer vision, multimodal learning, and human-computer interaction, as well as in culture and heritage. In recent years, with the raising of video retrieval tasks, methods in retrieving video content with natural language (text-to-video retrieval) gained quite some attention and have reached a performance level where real-world application is on the horizon. Appealing as it may sound, such methods focus on retrieving videos using plain visual-focused descriptions of what has happened in the video and finding videos such as instructions. It is too early to say such methods would be the new paradigms for accessing and encoding complex video content into high-dimensional data, but they are indeed innovative attempts and foundations to build future exploratory interfaces for AV archives (e.g. allow users to write stories and retrieve related snippets in the archive, or encoding video content at high-level for visualisation). This work filled the application gap by examining such text-to-video retrieval methods from an implementation point of view and proposed and verified a classifier-enhanced workflow to allow better results when dealing with in-situ queries that might have been different from the training dataset. Such a workflow is then applied to the real-world archive from T\'el\'evision Suisse Romande (RTS) to create a demo. At last, a human-centred evaluation is conducted to understand whether the text-to-video retrieval methods improve the overall experience of accessing AV archives. less