By: Anna M. Maddux, Maryam Kamgarpour
We consider the problem of learning to play a repeated contextual game with unknown reward and unknown constraints functions. Such games arise in applications where each agent's action needs to belong to a feasible set, but the feasible set is a priori unknown. For example, in constrained multi-agent reinforcement learning, the constraints on the agents' policies are a function of the unknown dynamics and hence, are themselves unknown. Unde... more
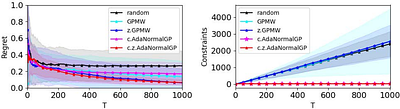
We consider the problem of learning to play a repeated contextual game with unknown reward and unknown constraints functions. Such games arise in applications where each agent's action needs to belong to a feasible set, but the feasible set is a priori unknown. For example, in constrained multi-agent reinforcement learning, the constraints on the agents' policies are a function of the unknown dynamics and hence, are themselves unknown. Under kernel-based regularity assumptions on the unknown functions, we develop a no-regret, no-violation approach which exploits similarities among different reward and constraint outcomes. The no-violation property ensures that the time-averaged sum of constraint violations converges to zero as the game is repeated. We show that our algorithm, referred to as c.z.AdaNormalGP, obtains kernel-dependent regret bounds and that the cumulative constraint violations have sublinear kernel-dependent upper bounds. In addition we introduce the notion of constrained contextual coarse correlated equilibria (c.z.CCE) and show that $\epsilon$-c.z.CCEs can be approached whenever players' follow a no-regret no-violation strategy. Finally, we experimentally demonstrate the effectiveness of c.z.AdaNormalGP on an instance of multi-agent reinforcement learning. less
By: Javier Cembrano, Svenja M. Griesbach, Maximilian J. Stahlberg
In the impartial selection problem, a subset of agents up to a fixed size $k$ among a group of $n$ is to be chosen based on votes cast by the agents themselves. A selection mechanism is impartial if no agent can influence its own chance of being selected by changing its vote. It is $\alpha$-optimal if, for every instance, the ratio between the votes received by the selected subset is at least a fraction of $\alpha$ of the votes received by ... more
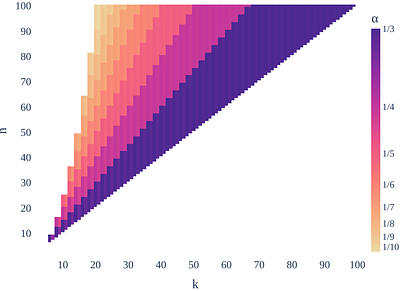
In the impartial selection problem, a subset of agents up to a fixed size $k$ among a group of $n$ is to be chosen based on votes cast by the agents themselves. A selection mechanism is impartial if no agent can influence its own chance of being selected by changing its vote. It is $\alpha$-optimal if, for every instance, the ratio between the votes received by the selected subset is at least a fraction of $\alpha$ of the votes received by the subset of size $k$ with the highest number of votes. We study deterministic impartial mechanisms in a more general setting with arbitrarily weighted votes and provide the first approximation guarantee, roughly $1/\lceil 2n/k\rceil$. When the number of agents to select is large enough compared to the total number of agents, this yields an improvement on the previously best known approximation ratio of $1/k$ for the unweighted setting. We further show that our mechanism can be adapted to the impartial assignment problem, in which multiple sets of up to $k$ agents are to be selected, with a loss in the approximation ratio of $1/2$. less
By: Yu Kato, Jiquan Xie, Tutomu Murase, Sumiko Miyata
For multi-transmission rate environments, access point (AP) connection methods have been proposed for maximizing system throughput, which is the throughput of an entire system, on the basis of the cooperative behavior of users. These methods derive optimal positions for the cooperative behavior of users, which means that new users move to improve the system throughput when connecting to an AP. However, the conventional method only considers... more
For multi-transmission rate environments, access point (AP) connection methods have been proposed for maximizing system throughput, which is the throughput of an entire system, on the basis of the cooperative behavior of users. These methods derive optimal positions for the cooperative behavior of users, which means that new users move to improve the system throughput when connecting to an AP. However, the conventional method only considers the transmission rate of new users and does not consider existing users, even though it is necessary to consider the transmission rate of all users to improve system throughput. In addition, these method do not take into account the frequency of interference between users. In this paper, we propose an AP connection method which maximizes system throughput by considering the interference between users and the initial position of all users. In addition, our proposed method can improve system throughput by about 6% at most compared to conventional methods. less
By: Marco Bornstein, Amrit Singh Bedi, Anit Kumar Sahu, Furqan Khan, Furong Huang
Edge device participation in federating learning (FL) has been typically studied under the lens of device-server communication (e.g., device dropout) and assumes an undying desire from edge devices to participate in FL. As a result, current FL frameworks are flawed when implemented in real-world settings, with many encountering the free-rider problem. In a step to push FL towards realistic settings, we propose RealFM: the first truly federa... more
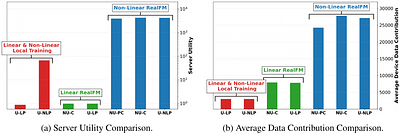
Edge device participation in federating learning (FL) has been typically studied under the lens of device-server communication (e.g., device dropout) and assumes an undying desire from edge devices to participate in FL. As a result, current FL frameworks are flawed when implemented in real-world settings, with many encountering the free-rider problem. In a step to push FL towards realistic settings, we propose RealFM: the first truly federated mechanism which (1) realistically models device utility, (2) incentivizes data contribution and device participation, and (3) provably removes the free-rider phenomena. RealFM does not require data sharing and allows for a non-linear relationship between model accuracy and utility, which improves the utility gained by the server and participating devices compared to non-participating devices as well as devices participating in other FL mechanisms. On real-world data, RealFM improves device and server utility, as well as data contribution, by up to 3 magnitudes and 7x respectively compared to baseline mechanisms. less
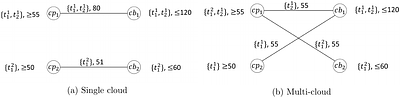
By: Segev Wasserkrug, Takayuki Osogami
In enterprise cloud computing, there is a big and increasing investment to move to multi-cloud computing, which allows enterprises to seamlessly utilize IT resources from multiple cloud providers, so as to take advantage of different cloud providers' capabilities and costs. This investment raises several key questions: Will multi-cloud always be more beneficial to the cloud users? How will this impact the cloud providers? Is it possible to ... more
In enterprise cloud computing, there is a big and increasing investment to move to multi-cloud computing, which allows enterprises to seamlessly utilize IT resources from multiple cloud providers, so as to take advantage of different cloud providers' capabilities and costs. This investment raises several key questions: Will multi-cloud always be more beneficial to the cloud users? How will this impact the cloud providers? Is it possible to create a multi-cloud market that is beneficial to all participants? In this work, we begin addressing these questions by using the game theoretic model of trading networks and formally compare between the single and multi-cloud markets. This comparson a) provides a sufficient condition under which the multi-cloud network can be considered more efficient than the single cloud one in the sense that a centralized coordinator having full information can impose an outcome that is strongly Pareto-dominant for all players and b) shows a surprising result that without centralized coordination, settings are possible in which even the cloud buyers' utilities may decrease when moving from a single cloud to a multi-cloud network. As these two results emphasize the need for centralized coordination to ensure a Pareto-dominant outcome and as the aforementioned Pareto-dominant result requires truthful revelation of participant's private information, we provide an automated mechanism design (AMD) approach, which, in the Bayesian setting, finds mechanisms which result in expectation in such Pareto-dominant outcomes, and in which truthful revelation of the parties' private information is the dominant strategy. We also provide empirical analysis to show the validity of our AMD approach. less
By: Anne-Kathrin Schmuck, K. S. Thejaswini, Irmak Sağlam, Satya Prakash Nayak
This paper considers the problem of solving infinite two-player games over finite graphs under various classes of progress assumptions motivated by applications in cyber-physical system (CPS) design. Formally, we consider a game graph G, a temporal specification $\Phi$ and a temporal assumption $\psi$, where both are given as linear temporal logic (LTL) formulas over the vertex set of G. We call the tuple $(G,\Phi,\psi)$ an 'augmented gam... more
This paper considers the problem of solving infinite two-player games over finite graphs under various classes of progress assumptions motivated by applications in cyber-physical system (CPS) design. Formally, we consider a game graph G, a temporal specification $\Phi$ and a temporal assumption $\psi$, where both are given as linear temporal logic (LTL) formulas over the vertex set of G. We call the tuple $(G,\Phi,\psi)$ an 'augmented game' and interpret it in the classical way, i.e., winning the augmented game $(G,\Phi,\psi)$ is equivalent to winning the (standard) game $(G,\psi \implies \Phi)$. Given a reachability or parity game $(G,\Phi)$ and some progress assumption $\psi$, this paper establishes whether solving the augmented game $(G,\Phi,\psi)$ lies in the same complexity class as solving $(G,\Phi)$. While the answer to this question is negative for arbitrary combinations of $\Phi$ and $\psi$, a positive answer results in more efficient algorithms, in particular for large game graphs. We therefore restrict our attention to particular classes of CPS-motivated progress assumptions and establish the worst-case time complexity of the resulting augmented games. Thereby, we pave the way towards a better understanding of assumption classes that can enable the development of efficient solution algorithms in augmented two-player games. less
By: Richard Willis, Yali Du, Joel Z Leibo, Michael Luck
Multi-agent cooperation is an important topic, and is particularly challenging in mixed-motive situations where it does not pay to be nice to others. Consequently, self-interested agents often avoid collective behaviour, resulting in suboptimal outcomes for the group. In response, in this paper we introduce a metric to quantify the disparity between what is rational for individual agents and what is rational for the group, which we call the... more
Multi-agent cooperation is an important topic, and is particularly challenging in mixed-motive situations where it does not pay to be nice to others. Consequently, self-interested agents often avoid collective behaviour, resulting in suboptimal outcomes for the group. In response, in this paper we introduce a metric to quantify the disparity between what is rational for individual agents and what is rational for the group, which we call the general self-interest level. This metric represents the maximum proportion of individual rewards that all agents can retain while ensuring that achieving social welfare optimum becomes a dominant strategy. By aligning the individual and group incentives, rational agents acting to maximise their own reward will simultaneously maximise the collective reward. As agents transfer their rewards to motivate others to consider their welfare, we diverge from traditional concepts of altruism or prosocial behaviours. The general self-interest level is a property of a game that is useful for assessing the propensity of players to cooperate and understanding how features of a game impact this. We illustrate the effectiveness of our method on several novel games representations of social dilemmas with arbitrary numbers of players. less
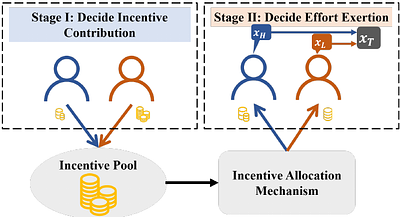
By: Kexin Chen, Chao Huang, Jianwei Huang
Information Elicitation Without Verification (IEWV) refers to the problem of eliciting high-accuracy solutions from crowd members when the ground truth is unverifiable. A high-accuracy team solution (aggregated from members' solutions) requires members' effort exertion, which should be incentivized properly. Previous research on IEWV mainly focused on scenarios where a central entity (e.g., the crowdsourcing platform) provides incentives to... more
Information Elicitation Without Verification (IEWV) refers to the problem of eliciting high-accuracy solutions from crowd members when the ground truth is unverifiable. A high-accuracy team solution (aggregated from members' solutions) requires members' effort exertion, which should be incentivized properly. Previous research on IEWV mainly focused on scenarios where a central entity (e.g., the crowdsourcing platform) provides incentives to motivate crowd members. Still, the proposed designs do not apply to practical situations where no central entity exists. This paper studies the overlooked decentralized IEWV scenario, where crowd members act as both incentive contributors and task solvers. We model the interactions among members with heterogeneous team solution accuracy valuations as a two-stage game, where each member decides her incentive contribution strategy in Stage 1 and her effort exertion strategy in Stage 2. We analyze members' equilibrium behaviors under three incentive allocation mechanisms: Equal Allocation (EA), Output Agreement (OA), and Shapley Value (SV). We show that at an equilibrium under any allocation mechanism, a low-valuation member exerts no more effort than a high-valuation member. Counter-intuitively, a low-valuation member provides incentives to the collaboration while a high-valuation member does not at an equilibrium under SV. This is because a high-valuation member who values the aggregated team solution more needs fewer incentives to exert effort. In addition, when members' valuations are sufficiently heterogeneous, SV leads to team solution accuracy and social welfare no smaller than EA and OA. less
By: Yuqing Kong
This paper presents a distributed communication model to investigate multistable perception, where a stimulus gives rise to multiple competing perceptual interpretations. We formalize stable perception as consensus achieved through components exchanging information. Our key finding is that relationships between components influence monostable versus multistable perceptions. When components contain substitute information about the prediction... more
This paper presents a distributed communication model to investigate multistable perception, where a stimulus gives rise to multiple competing perceptual interpretations. We formalize stable perception as consensus achieved through components exchanging information. Our key finding is that relationships between components influence monostable versus multistable perceptions. When components contain substitute information about the prediction target, stimuli display monostability. With complementary information, multistability arises. We then analyze phenomena like order effects and switching costs. Finally, we provide two additional perspectives. An optimization perspective balances accuracy and communication costs, relating stability to local optima. A Prediction market perspective highlights the strategic behaviors of neural coordination and provides insights into phenomena like rivalry, inhibition, and mental disorders. The two perspectives demonstrate how relationships among components influence perception costs, and impact competition and coordination behaviors in neural dynamics. less
By: Gennaro Auricchio, Qun Ma, Jie Zhang
In this paper, we explore the Mechanism Design aspects of the Maximum Vertex-weighted $b$-Matching (MVbM) problem on bipartite graphs $(A\cup T, E)$. The set $A$ comprises agents, while $T$ represents tasks. The set $E$ is the private information of either agents or tasks. In this framework, we investigate three mechanisms - $\MB$, $\MD$, and $\MG$ - that, given an MVbM problem as input, return a $b$-matching. We examine scenarios in which ... more
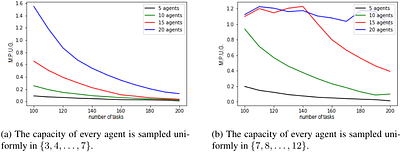
In this paper, we explore the Mechanism Design aspects of the Maximum Vertex-weighted $b$-Matching (MVbM) problem on bipartite graphs $(A\cup T, E)$. The set $A$ comprises agents, while $T$ represents tasks. The set $E$ is the private information of either agents or tasks. In this framework, we investigate three mechanisms - $\MB$, $\MD$, and $\MG$ - that, given an MVbM problem as input, return a $b$-matching. We examine scenarios in which either agents or tasks are strategic and report their adjacent edges to one of the three mechanisms. In both cases, we assume that the strategic entities are bounded by their statements: they can hide edges, but they cannot report edges that do not exist. First, we consider the case in which agents can manipulate. In this framework, $\MB$ and $\MD$ are optimal but not truthful. By characterizing the Nash Equilibria induced by $\MB$ and $\MD$, we reveal that both mechanisms have a Price of Anarchy ($PoA$) and Price of Stability ($PoS$) of $2$. These efficiency guarantees are tight; no deterministic mechanism can achieve a lower $PoA$ or $PoS$. In contrast, the third mechanism, $\MG$, is not optimal, but truthful and its approximation ratio is $2$. We demonstrate that this ratio is optimal; no deterministic and truthful mechanism can outperform it. We then shift our focus to scenarios where tasks can exhibit strategic behaviour. In this case, $\MB$, $\MD$, and $\MG$ all maintain truthfulness, making $\MB$ and $\MD$ truthful and optimal mechanisms. In conclusion, we investigate the manipulability of $\MB$ and $\MD$ through experiments on randomly generated graphs. We observe that (1) $\MB$ is less prone to be manipulated by the first agent than $\MD$ (2) $\MB$ is more manipulable on instances in which the total capacity of the agents is equal to the number of tasks (3) randomizing the agents' order reduces the agents' ability to manipulate $\MB$. less