By: M. Fuat Kına, Erdem Yörük, Ali Hürriyetoğlu, Melih Can Yardı, Şükrü Atsızelti, Fırat Duruşan, Oğuz Gürerk, Tolga Etgü, Zübeyir Nişancı, Osman Mutlu, Gizem Bacaksızlar Turbic, Yusuf Akbulut
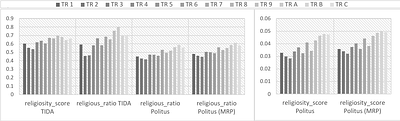
This paper tests the validity of a digital trace database (Politus) obtained from Twitter, with a recently conducted representative social survey, focusing on the use case of religiosity in Turkey. Religiosity scores in the research are extracted using supervised machine learning under the Politus project. The validation analysis depends on two steps. First, we compare the performances of two alternative tweet-to-user transformation strateg... more
This paper tests the validity of a digital trace database (Politus) obtained from Twitter, with a recently conducted representative social survey, focusing on the use case of religiosity in Turkey. Religiosity scores in the research are extracted using supervised machine learning under the Politus project. The validation analysis depends on two steps. First, we compare the performances of two alternative tweet-to-user transformation strategies, and second, test for the impact of resampling via the MRP technique. Estimates of the Politus are examined at both aggregate and region-level. The results are intriguing for future research on measuring public opinion via social media data. less
Predicting COVID-19 Infections Using Multi-layer Centrality Measures in Population-scale Networks
0upvotes
By: Christine Hedde-von Westernhagen, Javier Garcia-Bernardo, Ayoub Bagheri
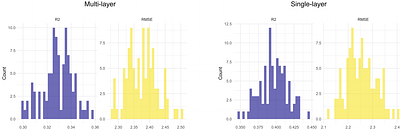
Understanding the spread of SARS-CoV-2 has been one of the most pressing problems of the recent past. Network models present a potent approach to studying such spreading phenomena because of their ability to represent complex social interactions. While previous studies have shown that network centrality measures are generally able to identify influential spreaders in a susceptible population, it is not yet known if they can also be used to ... more
Understanding the spread of SARS-CoV-2 has been one of the most pressing problems of the recent past. Network models present a potent approach to studying such spreading phenomena because of their ability to represent complex social interactions. While previous studies have shown that network centrality measures are generally able to identify influential spreaders in a susceptible population, it is not yet known if they can also be used to predict infection risks. However, information about infection risks at the individual level is vital for the design of targeted interventions. Here, we use large-scale administrative data from the Netherlands to study whether centrality measures can predict the risk and timing of infections with COVID-19-like diseases. We investigate this issue leveraging the framework of multi-layer networks, which accounts for interactions taking place in different contexts, such as workplaces, households and schools. In epidemic models simulated on real-world network data from over one million individuals, we find that existing centrality measures offer good predictions of relative infection risks, and are correlated with the timing of individual infections. We however find no association between centrality measures and real SARS-CoV-2 test data, which indicates that population-scale network data alone cannot aid predictions of virus transmission. less
By: Mohammadreza Doostmohammadian, Houman Zarrabi, Azam Doustmohammadian, Hamid R. Rabiee
Understanding the impact of network clustering and small-world properties on epidemic spread can be crucial in developing effective strategies for managing and controlling infectious diseases. Particularly in this work, we study the impact of these network features on targeted intervention (e.g., self-isolation and quarantine). The targeted individuals for self-isolation are based on centrality measures and node influence metrics. Compared ... more
Understanding the impact of network clustering and small-world properties on epidemic spread can be crucial in developing effective strategies for managing and controlling infectious diseases. Particularly in this work, we study the impact of these network features on targeted intervention (e.g., self-isolation and quarantine). The targeted individuals for self-isolation are based on centrality measures and node influence metrics. Compared to our previous works on scale-free networks, small-world networks are considered in this paper. Small-world networks resemble real-world social and human networks. In this type of network, most nodes are not directly connected but can be reached through a few intermediaries (known as the small-worldness property). Real social networks, such as friendship networks, also exhibit this small-worldness property, where most people are connected through a relatively small number of intermediaries. We particularly study the epidemic curve flattening by centrality-based interventions/isolation over small-world networks. Our results show that high clustering while having low small-worldness (higher shortest path characteristics) implies flatter infection curves. In reality, a flatter infection curve implies that the number of new cases of a disease is spread out over a longer period of time, rather than a sharp and sudden increase in cases (a peak in epidemic). In turn, this reduces the strain on healthcare resources and helps to relieve the healthcare services. less
By: Jiaxi Pu, Yanhao Wang, Yuchen Li, Xuan Zhou
Temporal bipartite graphs are widely used to denote time-evolving relationships between two disjoint sets of nodes, such as customer-product interactions in E-commerce and user-group memberships in social networks. Temporal butterflies, $(2,2)$-bicliques that occur within a short period and in a prescribed order, are essential in modeling the structural and sequential patterns of such graphs. Counting the number of temporal butterflies is t... more
Temporal bipartite graphs are widely used to denote time-evolving relationships between two disjoint sets of nodes, such as customer-product interactions in E-commerce and user-group memberships in social networks. Temporal butterflies, $(2,2)$-bicliques that occur within a short period and in a prescribed order, are essential in modeling the structural and sequential patterns of such graphs. Counting the number of temporal butterflies is thus a fundamental task in analyzing temporal bipartite graphs. However, existing algorithms for butterfly counting on static bipartite graphs and motif counting on temporal unipartite graphs are inefficient for this purpose. In this paper, we present a general framework with three sampling strategies for temporal butterfly counting. Since exact counting can be time-consuming on large graphs, our approach alternatively computes approximate estimates accurately and efficiently. We also provide analytical bounds on the number of samples each strategy requires to obtain estimates with small relative errors and high probability. We finally evaluate our framework on six real-world datasets and demonstrate its superior accuracy and efficiency compared to several baselines. Overall, our proposed framework and sampling strategies provide efficient and accurate approaches to approximating temporal butterfly counts on large-scale temporal bipartite graphs. less
By: Giuseppe Russo, Manoel Horta Ribeiro, Robert West
Fringe communities promoting conspiracy theories and extremist ideologies have thrived on mainstream platforms, raising questions about the mechanisms driving their growth. Here, we hypothesize and study a possible mechanism: new members may be recruited through fringe-interactions: the exchange of comments between members and non-members of fringe communities. We apply text-based causal inference techniques to study the impact of fringe-in... more
Fringe communities promoting conspiracy theories and extremist ideologies have thrived on mainstream platforms, raising questions about the mechanisms driving their growth. Here, we hypothesize and study a possible mechanism: new members may be recruited through fringe-interactions: the exchange of comments between members and non-members of fringe communities. We apply text-based causal inference techniques to study the impact of fringe-interactions on the growth of three prominent fringe communities on Reddit: r/Incel, r/GenderCritical, and r/The_Donald. Our results indicate that fringe-interactions attract new members to fringe communities. Users who receive these interactions are up to 4.2 percentage points (pp) more likely to join fringe communities than similar, matched users who do not. This effect is influenced by 1) the characteristics of communities where the interaction happens (e.g., left vs. right-leaning communities) and 2) the language used in the interactions. Interactions using toxic language have a 5pp higher chance of attracting newcomers to fringe communities than non-toxic interactions. We find no effect when repeating this analysis by replacing fringe (r/Incel, r/GenderCritical, and r/The_Donald) with non-fringe communities (r/climatechange, r/NBA, r/leagueoflegends), suggesting this growth mechanism is specific to fringe communities. Overall, our findings suggest that curtailing fringe-interactions may reduce the growth of fringe communities on mainstream platforms. less
By: Eunho Koo, Tongseok Lim
In the node classification task, it is intuitively understood that densely connected nodes tend to exhibit similar attributes. However, it is crucial to first define what constitutes a dense connection and to develop a reliable mathematical tool for assessing node cohesiveness. In this paper, we propose a probability-based objective function for semi-supervised node classification that takes advantage of higher-order networks' capabilities.... more
In the node classification task, it is intuitively understood that densely connected nodes tend to exhibit similar attributes. However, it is crucial to first define what constitutes a dense connection and to develop a reliable mathematical tool for assessing node cohesiveness. In this paper, we propose a probability-based objective function for semi-supervised node classification that takes advantage of higher-order networks' capabilities. The proposed function embodies the philosophy most aligned with the intuition behind classifying within higher-order networks, as it is designed to reduce the likelihood of nodes interconnected through higher-order networks bearing different labels. We evaluate the function using both balanced and imbalanced datasets generated by the Planted Partition Model (PPM), as well as a real-world political book dataset. According to the results, in challenging classification contexts characterized by low homo-connection probability, high hetero-connection probability, and limited prior information of nodes, higher-order networks outperform pairwise interactions in terms of objective function performance. Notably, the objective function exhibits elevated Recall and F1-score relative to Precision in the imbalanced dataset, indicating its potential applicability in many domains where detecting false negatives is critical, even at the expense of some false positives. less
Analysis and implementation of nanotargeting on LinkedIn based on publicly available non-PII
0upvotes
By: Ángel Merino, José González-Cabañas, Ángel Cuevas, Rubén Cuevas
A body of literature has shown multiple times that combining a few non-Personal Identifiable Information (non-PII) items is enough to make a user unique in a dataset including millions or even hundreds of millions of users. This work extends this area of research, demonstrating that a combination of a few non-PII publicly available attributes can be activated by a third party to individually target a user with hyper-personalized messages. T... more
A body of literature has shown multiple times that combining a few non-Personal Identifiable Information (non-PII) items is enough to make a user unique in a dataset including millions or even hundreds of millions of users. This work extends this area of research, demonstrating that a combination of a few non-PII publicly available attributes can be activated by a third party to individually target a user with hyper-personalized messages. This paper first implements a methodology demonstrating that the combination of the location and 6 rare (or 14 random) professional skills reported by a user in their LinkedIn profile is enough to become unique in a user base formed by $\sim$800M users with a probability of 75\%. A novel feature in this case, compared to previous works in the literature, is that the location and skills reported in a LinkedIn profile are publicly accessible to any other user or company registered in the platform and, in addition, can be activated through advertising campaigns. We ran a proof of concept experiment targeting three of the paper's authors. We demonstrated that all the ad campaigns configured with the location and $\geq$13 random professional skills retrieved from the authors' LinkedIn profiles successfully delivered ads exclusively to the targeted user. This practice is referred to as nanotargeting and may expose LinkedIn users to potential privacy and security risks such as malvertising or manipulation. less
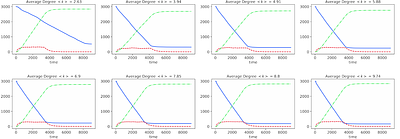
SeCoNet: A Heterosexual Contact Network Growth Model for Human Papillomavirus Disease Simulation
0upvotes
By: Weiyi Wang, Mahendra Piraveenan
Human Papillomavirus infection is the most common sexually transmitted infection, and causes serious complications such as cervical cancer in vulnerable female populations in regions such as East Africa. Due to the scarcity of empirical data about sexual relationships in varying demographics, computationally modelling the underlying sexual contact networks is important to understand Human Papillomavirus infection dynamics and prevention str... more
Human Papillomavirus infection is the most common sexually transmitted infection, and causes serious complications such as cervical cancer in vulnerable female populations in regions such as East Africa. Due to the scarcity of empirical data about sexual relationships in varying demographics, computationally modelling the underlying sexual contact networks is important to understand Human Papillomavirus infection dynamics and prevention strategies. In this work we present SeCoNet, a heterosexual contact network growth model for Human Papillomavirus disease simulation. The growth model consists of three mechanisms that closely imitate real-world relationship forming and discontinuation processes in sexual contact networks. We demonstrate that the networks grown from this model are scale-free, as are the real world sexual contact networks, and we demonstrate that the model can be calibrated to fit different demographic contexts by using a range of parameters. We also undertake disease dynamics analysis of Human Papillomavirus infection using a compartmental epidemic model on the grown networks. The presented SeCoNet growth model is useful to computational epidemiologists who study sexually transmitted infections in general and Human Papillomavirus infection in particular. less
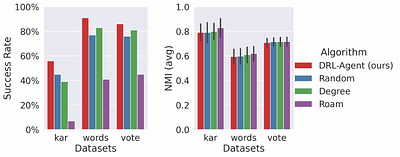
By: Andrea Bernini, Fabrizio Silvestri, Gabriele Tolomei
Community detection techniques are useful tools for social media platforms to discover tightly connected groups of users who share common interests. However, this functionality often comes at the expense of potentially exposing individuals to privacy breaches by inadvertently revealing their tastes or preferences. Therefore, some users may wish to safeguard their anonymity and opt out of community detection for various reasons, such as affi... more
Community detection techniques are useful tools for social media platforms to discover tightly connected groups of users who share common interests. However, this functionality often comes at the expense of potentially exposing individuals to privacy breaches by inadvertently revealing their tastes or preferences. Therefore, some users may wish to safeguard their anonymity and opt out of community detection for various reasons, such as affiliation with political or religious organizations. In this study, we address the challenge of community membership hiding, which involves strategically altering the structural properties of a network graph to prevent one or more nodes from being identified by a given community detection algorithm. We tackle this problem by formulating it as a constrained counterfactual graph objective, and we solve it via deep reinforcement learning. We validate the effectiveness of our method through two distinct tasks: node and community deception. Extensive experiments show that our approach overall outperforms existing baselines in both tasks. less
By: Shuo Zou, Bo Zhou, Qi Xuan
Degree correlation is an important characteristic of networks, which is usually quantified by the assortativity coefficient. However, concerns arise about changing the assortativity coefficient of a network when networks suffer from adversarial attacks. In this paper, we analyze the factors that affect the assortativity coefficient and study the optimization problem of maximizing or minimizing the assortativity coefficient (r) in rewired ne... more
Degree correlation is an important characteristic of networks, which is usually quantified by the assortativity coefficient. However, concerns arise about changing the assortativity coefficient of a network when networks suffer from adversarial attacks. In this paper, we analyze the factors that affect the assortativity coefficient and study the optimization problem of maximizing or minimizing the assortativity coefficient (r) in rewired networks with $k$ pairs of edges. We propose a greedy algorithm and formulate the optimization problem using integer programming to obtain the optimal solution for this problem. Through experiments, we demonstrate the reasonableness and effectiveness of our proposed algorithm. For example, rewired edges 10% in the ER network, the assortativity coefficient improved by 60%. less