By: Ludmila Botelho, Özlem Salehi
The Operational Fixed Interval Scheduling Problem aims to find an assignment of jobs to machines that maximizes the total weight of the completed jobs. We introduce a new variant of the problem where we consider the additional goal of minimizing the idle time, the total duration during which the machines are idle. The problem is expressed using quadratic unconstrained binary optimization (QUBO) formulation, taking into account soft and hard... more
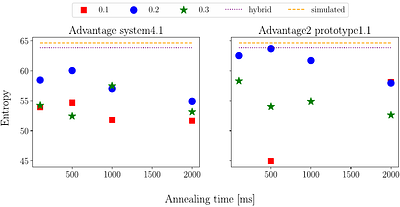
The Operational Fixed Interval Scheduling Problem aims to find an assignment of jobs to machines that maximizes the total weight of the completed jobs. We introduce a new variant of the problem where we consider the additional goal of minimizing the idle time, the total duration during which the machines are idle. The problem is expressed using quadratic unconstrained binary optimization (QUBO) formulation, taking into account soft and hard constraints required to ensure that the number of jobs running at a time point is desirably equal to the number of machines. Our choice of QUBO representation is motivated by the increasing popularity of new computational architectures such as neuromorphic processors, coherent Ising machines, and quantum and quantum-inspired digital annealers for which QUBO is a natural input. An optimization problem that can be solved using the presented QUBO formulation is the music reduction problem, the process of reducing a given music piece for a smaller number of instruments. We use two music compositions to test the QUBO formulation and compare the performance of simulated, quantum, and hybrid annealing algorithms. less
By: Ankit Bende, Simranjeet Singh, Chandan Kumar Jha, Tim Kempen, Felix Cüppers, Christopher Bengel, Andre Zambanini, Dennis Nielinger, Sachin Patkar, Rolf Drechsler, Rainer Waser, Farhad Merchant, Vikas Rana
Memristor-aided logic (MAGIC) design style holds a high promise for realizing digital logic-in-memory functionality. The ability to implement a specific gate in a MAGIC design style hinges on the SET-to-RESET threshold ratio. The TaOx memristive devices exhibit distinct SET-to-RESET ratios, enabling the implementation of OR and NOT operations. As the adoption of the MAGIC design style gains momentum, it becomes crucial to understand the bre... more
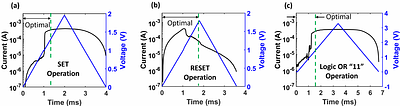
Memristor-aided logic (MAGIC) design style holds a high promise for realizing digital logic-in-memory functionality. The ability to implement a specific gate in a MAGIC design style hinges on the SET-to-RESET threshold ratio. The TaOx memristive devices exhibit distinct SET-to-RESET ratios, enabling the implementation of OR and NOT operations. As the adoption of the MAGIC design style gains momentum, it becomes crucial to understand the breakdown of energy consumption in the various phases of its operation. This paper presents experimental demonstrations of the OR and NOT gates on a 1T1R crossbar array. Additionally, it provides insights into the energy distribution for performing these operations at different stages. Through our experiments across different gates, we found that the energy consumption is dominated by initialization in the MAGIC design style. The energy split-up is 14.8%, 85%, and 0.2% for execution, initialization, and read operations respectively. less
By: Shuvro Chowdhury, Kerem Y. Camsari
The slowing down of Moore's Law has led to a crisis as the computing workloads of Artificial Intelligence (AI) algorithms continue skyrocketing. There is an urgent need for scalable and energy-efficient hardware catering to the unique requirements of AI algorithms and applications. In this environment, probabilistic computing with p-bits emerged as a scalable, domain-specific, and energy-efficient computing paradigm, particularly useful for... more
The slowing down of Moore's Law has led to a crisis as the computing workloads of Artificial Intelligence (AI) algorithms continue skyrocketing. There is an urgent need for scalable and energy-efficient hardware catering to the unique requirements of AI algorithms and applications. In this environment, probabilistic computing with p-bits emerged as a scalable, domain-specific, and energy-efficient computing paradigm, particularly useful for probabilistic applications and algorithms. In particular, spintronic devices such as stochastic magnetic tunnel junctions (sMTJ) show great promise in designing integrated p-computers. Here, we examine how a scalable probabilistic computer with such magnetic p-bits can be useful for an emerging field combining machine learning and quantum physics. less
By: Javier Lopez-Randulfe, Nico Reeb, Alois Knoll
Processing sensor data with spiking neural networks on digital neuromorphic chips requires converting continuous analog signals into spike pulses. Two strategies are promising for achieving low energy consumption and fast processing speeds in end-to-end neuromorphic applications. First, to directly encode analog signals to spikes to bypass the need for an analog-to-digital converter (ADC). Second, to use temporal encoding techniques to maxi... more
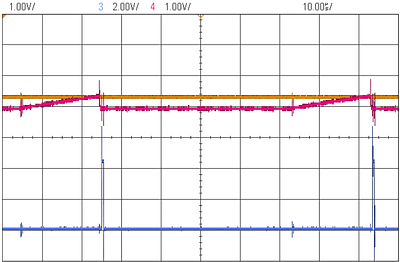
Processing sensor data with spiking neural networks on digital neuromorphic chips requires converting continuous analog signals into spike pulses. Two strategies are promising for achieving low energy consumption and fast processing speeds in end-to-end neuromorphic applications. First, to directly encode analog signals to spikes to bypass the need for an analog-to-digital converter (ADC). Second, to use temporal encoding techniques to maximize the spike sparsity, which is a crucial parameter for fast and efficient neuromorphic processing. In this work, we propose an adaptive control of the refractory period of the leaky integrate-and-fire (LIF) neuron model for encoding continuous analog signals into a train of time-coded spikes. The LIF-based encoder generates phase-encoded spikes that are compatible with digital hardware. We implemented the neuron model on a physical circuit and tested it with different electric signals. A digital neuromorphic chip processed the generated spike trains and computed the signal's frequency spectrum using a spiking version of the Fourier transform. We tested the prototype circuit on electric signals up to 1 KHz. Thus, we provide an end-to-end neuromorphic application that generates the frequency spectrum of an electric signal without the need for an ADC or a digital signal processing algorithm. less
By: Manos Kirtas, Nikolaos Passalis, Nikolaos Pleros, Anastasios Tefas
Neuromorphic photonic accelerators are becoming increasingly popular, since they can significantly improve computation speed and energy efficiency, leading to femtojoule per MAC efficiency. However, deploying existing DL models on such platforms is not trivial, since a great range of photonic neural network architectures relies on incoherent setups and power addition operational schemes that cannot natively represent negative quantities. Th... more
Neuromorphic photonic accelerators are becoming increasingly popular, since they can significantly improve computation speed and energy efficiency, leading to femtojoule per MAC efficiency. However, deploying existing DL models on such platforms is not trivial, since a great range of photonic neural network architectures relies on incoherent setups and power addition operational schemes that cannot natively represent negative quantities. This results in additional hardware complexity that increases cost and reduces energy efficiency. To overcome this, we can train non-negative neural networks and potentially exploit the full range of incoherent neuromorphic photonic capabilities. However, existing approaches cannot achieve the same level of accuracy as their regular counterparts, due to training difficulties, as also recent evidence suggests. To this end, we introduce a methodology to obtain the non-negative isomorphic equivalents of regular neural networks that meet requirements of neuromorphic hardware, overcoming the aforementioned limitations. Furthermore, we also introduce a sign-preserving optimization approach that enables training of such isomorphic networks in a non-negative manner. less