Neural Subspace Reallocation: Continual Learning as Retrieval-Based Subspace Memory Management
0upvotes
By: Byeong Hoon Yoon
We introduce Neural Subspace Reallocation (NSR), which reframes continual learning as memory management over parameter subspaces. Instead of treating Low-Rank Adaptation (LoRA) modules as disposable per-task adapters, NSR manages them as compressible, retrievable memory units on a frozen backbone through a recurring cycle: (1) compress learned LoRAs via SVD, (2) reserve them in a TaskKnowledgeBank, (3) recall related past LoRAs by embedding s... more
We introduce Neural Subspace Reallocation (NSR), which reframes continual learning as memory management over parameter subspaces. Instead of treating Low-Rank Adaptation (LoRA) modules as disposable per-task adapters, NSR manages them as compressible, retrievable memory units on a frozen backbone through a recurring cycle: (1) compress learned LoRAs via SVD, (2) reserve them in a TaskKnowledgeBank, (3) recall related past LoRAs by embedding similarity to warm-start new or returning tasks, and (4) reallocate the active subspace accordingly, with distillation protecting prior tasks. We prove that in cyclic environments any memoryless allocation policy incurs cumulative regret Omega(T(M-1)Delta_switch) relative to a history-aware policy backed by the Bank (Theorem 1). Empirically, on Split-CIFAR-100 the Bank reduces cyclic recovery time by 10x, exactly as predicted, and on the heterogeneous 5-Datasets benchmark NSR achieves the highest accuracy and the least forgetting, about 9x closer to zero backward transfer than the memoryless heuristics. Crucially, we run a controlled study that isolates which component matters: holding the Bank fixed and varying only the allocation rule, we find that a simple similarity-based retrieval rule matches or beats a learned reinforcement-learning controller (recovering recurring tasks in 0 vs 1.8 steps and reaching equal accuracy). Our central, honest finding is therefore that the memory mechanism -- compression and similarity retrieval -- rather than a learned allocation policy, drives continual-learning performance under fixed capacity. A memory-budget analysis confirms the compressed Bank stays small -- 0.29 MB of parameter memory per task -- so a top-K retention cap bounds the total footprint while preserving fast recovery for retained tasks. less
By: Matthias Blaschke, Daniel Kienzle, Zsuzsanna Koczor-Benda, Julian Lorenz, Rainer Lienhart, Fabian Pauly
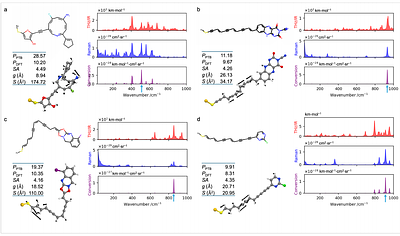
Generative molecular design is shaped by simple proxy benchmarks for drug-like properties and models pretrained on large pharmaceutical datasets. This combination yields strong benchmark metrics but limits transferability to domains structurally distinct from drug discovery. To overcome this limitation and drive discovery toward real, scientifically grounded targets, we introduce the Nanotechnology Molecular Optimization (NMO) Benchmark, whic... more
Generative molecular design is shaped by simple proxy benchmarks for drug-like properties and models pretrained on large pharmaceutical datasets. This combination yields strong benchmark metrics but limits transferability to domains structurally distinct from drug discovery. To overcome this limitation and drive discovery toward real, scientifically grounded targets, we introduce the Nanotechnology Molecular Optimization (NMO) Benchmark, which bridges machine learning (ML) and quantum materials science. NMO acts simultaneously as a rigorous testbed for the ML community and a discovery engine for nanotechnology research. The suite replaces proxy oracles with quantum simulations and introduces strict protocols that prioritize scientific utility over leaderboard-oriented overfitting. The physics-based NMO tasks impose hard structural constraints and rugged fitness landscapes, posing fundamentally new requirements on generative models. Notably, advanced molecular optimization methods underperform much simpler approaches on the NMO tasks. We develop a new baseline method identifying the critical components to solve the NMO tasks, including a novel representation for modeling structural constraints and a domain-agnostic pretraining strategy to eliminate pharmaceutical dataset bias. Our results surpass state-of-the-art physical properties and reveal previously unknown structural motifs, offering new insights for the nanotechnology community and demonstrating that ML can drive genuine scientific discovery. less
By: Bertram Taetz, Hugo Albuquerque Cosme da Silva, Gabriele Bleser-Taetz
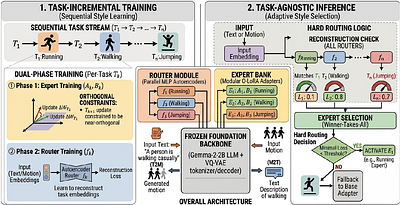
Motion-language agents must possess the bidirectional capability to both understand human movement (motion-to-text, M2T) and generate it from natural language (text-to-motion, T2M). While foundational models have achieved strong performance in static settings, autonomous agents operating in dynamic environments must continuously incorporate new motion concepts -- such as novel athletic styles or specialized gestures -- without catastrophic fo... more
Motion-language agents must possess the bidirectional capability to both understand human movement (motion-to-text, M2T) and generate it from natural language (text-to-motion, T2M). While foundational models have achieved strong performance in static settings, autonomous agents operating in dynamic environments must continuously incorporate new motion concepts -- such as novel athletic styles or specialized gestures -- without catastrophic forgetting of previously acquired skills. We investigate the stability-plasticity trade-off in bidirectional motion-language learning under sequential task exposure. Building on a frozen large language model backbone, we introduce low-rank adaptation (LoRA) variants designed to mitigate inter-task interference. We specifically propose mixture-of-experts architectures that utilize an autoencoder-based router to select task-specific experts at inference time, so that no task-label is needed. To evaluate these methods, we establish a reproducible five-task benchmark derived from HumanML3D through semantic clustering of motion descriptions. Our experimental results demonstrate near-zero forgetting across both M2T and T2M directions while maintaining high generation and captioning quality. Furthermore, we show that hard expert selection via routing significantly outperforms soft expert blending in quality metrics, indicating that preserving expert isolation is critical for maintaining performance in our continual learning setting. Finally, we observe that a divergence between token-level accuracy and downstream generation quality may occur, highlighting the need for more comprehensive evaluation protocols in future research on lifelong motion-language agents. less
By: Zeynep Türkmen, Kürşat Kaya, Alexander Pfefferle, Frank Hutter
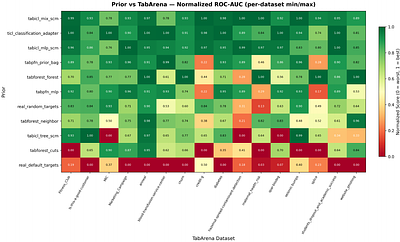
Data-generating priors are a central component of tabular foundation models because they define the task distribution used during pretraining. However, priors are rarely evaluated as independent components, making it difficult to understand how much they affect downstream model behavior. This raises a methodological question: how can priors from different tabular foundation models be compared independently of the architectures and training pr... more
Data-generating priors are a central component of tabular foundation models because they define the task distribution used during pretraining. However, priors are rarely evaluated as independent components, making it difficult to understand how much they affect downstream model behavior. This raises a methodological question: how can priors from different tabular foundation models be compared independently of the architectures and training protocols they were introduced with? To study this question, we implement a unified interface for publicly available priors from recent tabular foundation models and priors constructed from real datasets. We generate training tasks from each prior, train the same model architecture under a fixed training protocol, and evaluate the resulting models on shared downstream classification tasks. We compare priors through both generated-task statistics and downstream predictive performance. Our results show that different priors favor different downstream behaviors, with some achieving stronger absolute performance and others exhibiting more consistent relative rankings across datasets. We further find that data-level similarity only partially explains downstream behavior. Our code is available at https://github.com/automl/TFM-Playground/tree/prior-dev. less
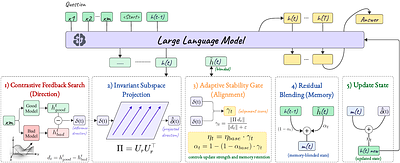
By: Arun Vignesh Malarkkan, Manan Roy Choudhury, Utkarsh Byahut, Yash Ravindra Charde, Vivek Gupta, Yanjie Fu
Latent reasoning models perform multi-step inference directly in hidden-state space, yet the structure of these latent reasoning trajectories remains poorly understood. We show that contrastive refinement signals between stronger and weaker reasoning trajectories exhibit a highly concentrated low-rank structure, while unconstrained latent updates remain sensitive to paraphrases, checkpoint choice, and trajectory perturbations. These observati... more
Latent reasoning models perform multi-step inference directly in hidden-state space, yet the structure of these latent reasoning trajectories remains poorly understood. We show that contrastive refinement signals between stronger and weaker reasoning trajectories exhibit a highly concentrated low-rank structure, while unconstrained latent updates remain sensitive to paraphrases, checkpoint choice, and trajectory perturbations. These observations suggest that latent reasoning trajectories contain stable invariant directions mixed with unstable instance-specific variation. We introduce \textbf{Trajectory-Invariant Latent Refinement (TILR)}, a training-free intervention framework for identifying and manipulating stable reasoning directions in latent space. TILR first learns a low-rank invariant subspace from contrastive trajectory differences across inputs, then constrains latent interventions to this subspace while suppressing poorly aligned updates through an adaptive alignment gate. Across six reasoning benchmarks, we find that a small number of latent directions explain most variation between strong and weak reasoning trajectories. Interventions on these directions causally improve reasoning consistency and reduce trajectory instability under paraphrases and perturbations. TILR improves answer consistency under paraphrase by ~10% and reduces latent trajectory variance by up to $50\%$ while preserving reasoning accuracy. These results support a geometric view of latent reasoning in which transferable reasoning behavior emerges from stable low-dimensional structure within hidden-state trajectories. less
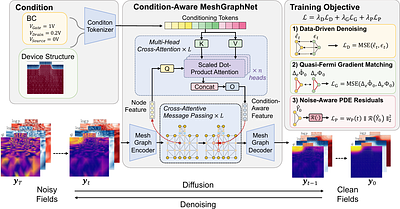
By: Yihan Zhang, Zhiteng Zhang, Kun Chen, Chen Wang
Technology computer-aided design (TCAD) semiconductor device simulation is fundamentally constrained by the high computational cost of iteratively solving coupled drift-diffusion equations. Existing ML surrogates either reduce internal physics to macroscopic scalar regressions, or rely on single-step mappings that lack the iterative refinement required to resolve stiff, coupled fields. To address this, we introduce PCGD, a Physics-Guided Cond... more
Technology computer-aided design (TCAD) semiconductor device simulation is fundamentally constrained by the high computational cost of iteratively solving coupled drift-diffusion equations. Existing ML surrogates either reduce internal physics to macroscopic scalar regressions, or rely on single-step mappings that lack the iterative refinement required to resolve stiff, coupled fields. To address this, we introduce PCGD, a Physics-Guided Conditional Graph Diffusion framework operating natively on unstructured TCAD meshes to predict coupled electrostatic and carrier density fields. PCGD employs a Condition-Aware MeshGraphNet denoiser that explicitly injects boundary conditions and device structure context via global cross-attention. By augmenting data-driven denoising with a physics-guided hybrid objective that integrates exponent-free quasi-Fermi gradient matching with noise-aware PDE residuals, PCGD progressively enforce physical constraints in the iterative diffusion trajectory. This strategy successfully bypasses the numerical instabilities typical of stiff drift-diffusion equations. Evaluated on a challenging mixed PN/MOS benchmark, PCGD significantly outperforms deterministic one-step regression (1.207% error) and local diffusion (1.585% error) baselines by achieving a sub-percent mean relative field error of 0.835%, while concurrently reducing maximum PDE residual errors by nearly three orders of magnitude compared to pure diffusion. It also transfers robustly to unseen SOI topologies (0.815% error) via LoRA adaptation, using 5.30$\times$ less data and 14.34$\times$ fewer parameters than full fine-tuning. Ultimately, PCGD bridges the computational efficiency of generative surrogates with the rigorous physical fidelity of traditional TCAD, unlocking highly scalable, field-level analysis for robust device engineering. less
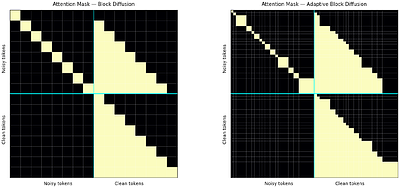
Adaptive Block Diffusion: Resolving Training-Inference Mismatch in Diffusion Language Models
0upvotes
By: Gagan Jain
Diffusion Language Models (DLMs) are typically trained under fixed context structures, restricting denoising to predetermined token subsets. This creates a mismatch between training and inference, where models must operate over arbitrary configurations, leading to degradation off the training grid. We propose Adaptive Block Diffusion (ABD), which resolves this mismatch by optimizing denoising risk over a distribution of prefix-window configur... more
Diffusion Language Models (DLMs) are typically trained under fixed context structures, restricting denoising to predetermined token subsets. This creates a mismatch between training and inference, where models must operate over arbitrary configurations, leading to degradation off the training grid. We propose Adaptive Block Diffusion (ABD), which resolves this mismatch by optimizing denoising risk over a distribution of prefix-window configurations. By treating the configuration as a stochastic variable, ABD trains a single model over the full configuration space without architectural changes. We show that generalization across decoding strategies is governed by the support of the training distribution, and that ABD guarantees denoising optimality for any inference policy whose configurations are covered during training. Empirically, ABD exhibits structural invariance across decoding scales, avoiding off-grid collapse and recovering a monotonic relationship between block size and perplexity, while matching or outperforming fixed-block specialists at their target scales. less

Beyond the Hard Budget: Sparsity Regularizers for More Interpretable Top-k Sparse Autoencoders
0upvotes
By: Nathanaël Jacquier, Maria Vakalopoulou, Mahdi S. Hosseini
Sparse autoencoders (SAEs) have become a leading tool for interpreting the representations of vision foundation models, decomposing their polysemantic activations into a larger set of sparse, more monosemantic features. The Top-$k$ SAE, a now-standard variant, enforces sparsity architecturally through its activation function, retaining only the $k$ most active latents per input. Because it was designed precisely to avoid the $\ell_1$ penalty ... more
Sparse autoencoders (SAEs) have become a leading tool for interpreting the representations of vision foundation models, decomposing their polysemantic activations into a larger set of sparse, more monosemantic features. The Top-$k$ SAE, a now-standard variant, enforces sparsity architecturally through its activation function, retaining only the $k$ most active latents per input. Because it was designed precisely to avoid the $\ell_1$ penalty used by earlier SAEs and its known drawbacks, it has not been combined with an explicit sparsity regularizer, despite retaining limitations of its own, such as a budget $k$ that is fixed regardless of input complexity and a tendency to overfit to the training value of $k$. We introduce two sparsity regularizers compatible with the Top-$k$ architecture, both acting on the activations before the Top-$k$ selection: an $\ell_1$ penalty on the unselected (off-support) units, and a scale-invariant $\ell_1/\ell_2$-ratio penalty that concentrates the code onto fewer effective units. Both penalties are applied only to the batch-active units, those selected by the Top-$k$ operator at least once within the batch. Across two datasets, three vision foundation models, and a range of $k$, both regularizers consistently improve monosemanticity at no cost to reconstruction quality. The $\ell_1/\ell_2$ penalty further concentrates information into fewer latents, making reconstruction more robust to the inference-time choice of $k$ and improving small-budget linear probing. Our central finding is that hard architectural sparsity and soft sparsity regularization are complementary rather than mutually exclusive. less
By: Nicklas Hansen, Xiaolong Wang
Modern generative world models render increasingly realistic action-controllable futures, yet they frequently hallucinate: rollouts remain visually fluent while drifting from the ground-truth dynamics. We hypothesize that hallucination concentrates in low-coverage regions of the state-action space, where lightweight data-centric signals can both detect it and guide mitigation. To test this, we introduce MMBench2, a 427-hour, 210-task dataset ... more
Modern generative world models render increasingly realistic action-controllable futures, yet they frequently hallucinate: rollouts remain visually fluent while drifting from the ground-truth dynamics. We hypothesize that hallucination concentrates in low-coverage regions of the state-action space, where lightweight data-centric signals can both detect it and guide mitigation. To test this, we introduce MMBench2, a 427-hour, 210-task dataset for visual world modeling with ground-truth actions, rewards, and live simulators, and train a 350M-parameter world model on it. We identify three distinct hallucination modes: perceptual, action-marginalized, and scene-diverging -- each anchored to a different stage of the pipeline, and develop three signals that accurately predict where the model will fail. To close coverage gaps at training time, we develop a coverage-aware sampling technique; to close them online, our hallucination predictors serve as curiosity rewards for targeted data collection, yielding a data-efficient finetuning recipe that adapts the pretrained world model to entirely unseen environments with as few as 50 real environment trajectories. Overall, our findings reveal that hallucination in world models is inherently a data coverage issue, and that the same signals used to detect it can also be used for mitigation. An interactive web version of our paper is available at https://www.nicklashansen.com/mmbench2 less
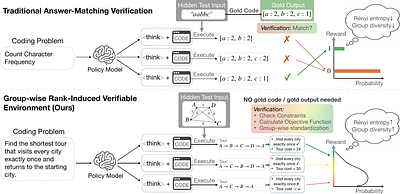
By: Yingyu Lin, Qiyue Gao, Nikki Lijing Kuang, Xunpeng Huang, Kun Zhou, Tongtong Liang, Zhewei Yao, Yi-An Ma, Yuxiong He
Reinforcement learning with verifiable rewards (RLVR) for training LLMs typically rely on ground-truth answers to assign rewards, limiting their applicability to tasks where the ground-truth solution is unknown. We introduce a \textbf{R}anking-\textbf{i}nduced \textbf{VER}ifiable framework (RiVER) that trains LLMs on score-based optimization tasks without ground-truth solutions, using deterministic execution feedback as continuous-valued supe... more
Reinforcement learning with verifiable rewards (RLVR) for training LLMs typically rely on ground-truth answers to assign rewards, limiting their applicability to tasks where the ground-truth solution is unknown. We introduce a \textbf{R}anking-\textbf{i}nduced \textbf{VER}ifiable framework (RiVER) that trains LLMs on score-based optimization tasks without ground-truth solutions, using deterministic execution feedback as continuous-valued supervision. When applying group-relative RL to such continuous rewards, we identify two key challenges: \emph{scale dominance}, where uncalibrated score magnitudes across test instances distort policy updates, and \emph{frequency dominance}, where repeatedly sampled suboptimal solutions can outweigh rare but stronger candidates. RiVER addresses these challenges with calibrated reward shaping that uses instance-wise comparisons and emphasizes top-ranked solvers while retaining bounded feedback for other valid solutions. We train on 12 AtCoder Heuristic Contest tasks and evaluate on Algorithm Engineering Benchmark (ALE-Bench), LiveCodeBench, and USACO. RiVER advances Qwen3-8B and GLM-Z1-9B-0414 by 8.9\% and 9.4\% in ALE rating rank. More importantly, despite training exclusively on score-based tasks without any ground-truth solutions, RiVER also improves the backbones across exact-solution benchmarks such as LiveCodeBench and USACO by an absolute average improvement of 2.4\% and 3.5\%. By contrast, baselines trained with raw execution scores improve ALE rating but fail to transfer to exact-solution benchmarks. These results suggest that score-based optimization tasks, combined with proper reward calibration, can serve as effective training environments for general coding ability without ground-truth solutions. less