By: Chenghao Li
Zhejiang University, Hangzhou, China, Yifei Wu
Zhejiang University, Hangzhou, China, Wenbo Shen
Zhejiang University, Hangzhou, China, Zichen Zhao
Zhejiang University, Hangzhou, China, Rui Chang
Zhejiang University, Hangzhou, China, Chengwei Liu
Nanyang Technological University, Singapore, Singapore, Yang Liu
Nanyang Technological University, Singapore, Singapore, Kui Ren
Zhejiang University, Hangzhou, China
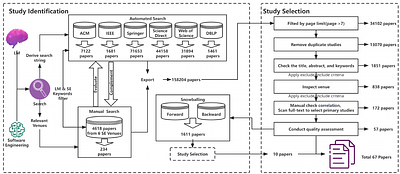
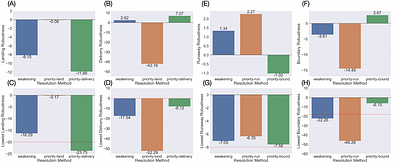
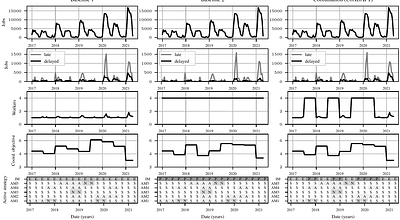
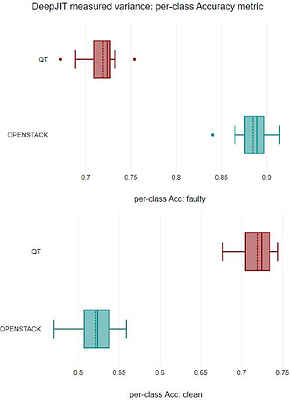
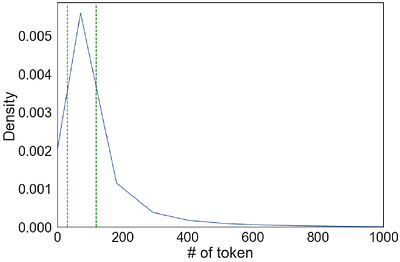
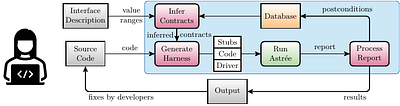
Rust programming language is gaining popularity rapidly in building reliable and secure systems due to its security guarantees and outstanding performance. To provide extra functionalities, the Rust compiler introduces Rust unstable features (RUF) to extend compiler functionality, syntax, and standard library support. However, these features are unstable and may get removed, introducing compilation failures to dependent packages. Even worse...
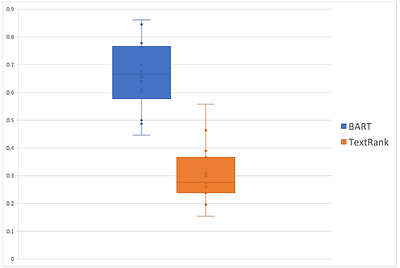
more Rust programming language is gaining popularity rapidly in building reliable and secure systems due to its security guarantees and outstanding performance. To provide extra functionalities, the Rust compiler introduces Rust unstable features (RUF) to extend compiler functionality, syntax, and standard library support. However, these features are unstable and may get removed, introducing compilation failures to dependent packages. Even worse, their impacts propagate through transitive dependencies, causing large-scale failures in the whole ecosystem. Although RUF is widely used in Rust, previous research has primarily concentrated on Rust code safety, with the usage and impacts of RUF from the Rust compiler remaining unexplored. Therefore, we aim to bridge this gap by systematically analyzing the RUF usage and impacts in the Rust ecosystem. We propose novel techniques for extracting RUF precisely, and to assess its impact on the entire ecosystem quantitatively, we accurately resolve package dependencies. We have analyzed the whole Rust ecosystem with 590K package versions and 140M transitive dependencies. Our study shows that the Rust ecosystem uses 1000 different RUF, and at most 44% of package versions are affected by RUF, causing compiling failures for at most 12%. To mitigate wide RUF impacts, we further design and implement a RUF-compilation-failure recovery tool that can recover up to 90% of the failure. We believe our techniques, findings, and tools can help to stabilize the Rust compiler, ultimately enhancing the security and reliability of the Rust ecosystem.
less