
By: Isha Chaudhary, Vedaant Jain, Avaljot Singh, Kavya Sachdeva, Sayan Ranu, Gagandeep Singh
We introduce the first principled framework, Lumos, for specifying and formally certifying Language Model System (LMS) behaviors. Lumos is an imperative probabilistic programming DSL over graphs, with constructs to generate independent and identically distributed prompts for LMS. It offers a structured view of prompt distributions via graphs, forming random prompts from sampled subgraphs. Lumos supports certifying LMS for arbitrary prompt dis... more
We introduce the first principled framework, Lumos, for specifying and formally certifying Language Model System (LMS) behaviors. Lumos is an imperative probabilistic programming DSL over graphs, with constructs to generate independent and identically distributed prompts for LMS. It offers a structured view of prompt distributions via graphs, forming random prompts from sampled subgraphs. Lumos supports certifying LMS for arbitrary prompt distributions via integration with statistical certifiers. We provide hybrid (operational and denotational) semantics for Lumos, providing a rigorous way to interpret the specifications. Using only a small set of composable constructs, Lumos can encode existing LMS specifications, including complex relational and temporal specifications. It also facilitates specifying new properties - we present the first safety specifications for vision-language models (VLMs) in autonomous driving scenarios developed with Lumos. Using these, we show that the state-of-the-art VLM Qwen-VL exhibits critical safety failures, producing incorrect and unsafe responses with at least 90% probability in right-turn scenarios under rainy driving conditions, revealing substantial safety risks. Lumos's modular structure allows easy modification of the specifications, enabling LMS certification to stay abreast with the rapidly evolving threat landscape. We further demonstrate that specification programs written in Lumos enable finding specific failure cases exhibited by state-of-the-art LMS. Lumos is the first systematic and extensible language-based framework for specifying and certifying LMS behaviors, paving the way for a wider adoption of LMS certification. less
By: Daniel Marshall University of Kent, Dominic Orchard University of Kent and University of Cambridge
Ownership and borrowing systems, designed to enforce safe memory management without the need for garbage collection, have been brought to the fore by the Rust programming language. Rust also aims to bring some guarantees offered by functional programming into the realm of performant systems code, but the type system is largely separate from the ownership model, with type and borrow checking happening in separate compilation phases. Recent m... more
Ownership and borrowing systems, designed to enforce safe memory management without the need for garbage collection, have been brought to the fore by the Rust programming language. Rust also aims to bring some guarantees offered by functional programming into the realm of performant systems code, but the type system is largely separate from the ownership model, with type and borrow checking happening in separate compilation phases. Recent models such as RustBelt and Oxide aim to formalise Rust in depth, but there is less focus on integrating the basic ideas into more traditional type systems. An approach designed to expose an essential core for ownership and borrowing would open the door for functional languages to borrow concepts found in Rust and other ownership frameworks, so that more programmers can enjoy their benefits. One strategy for managing memory in a functional setting is through uniqueness types, but these offer a coarse-grained view: either a value has exactly one reference, and can be mutated safely, or it cannot, since other references may exist. Recent work demonstrates that linear and uniqueness types can be combined in a single system to offer restrictions on program behaviour and guarantees about memory usage. We develop this connection further, showing that just as graded type systems like those of Granule and Idris generalise linearity, Rust's ownership model arises as a graded generalisation of uniqueness. We combine fractional permissions with grading to give the first account of ownership and borrowing that smoothly integrates into a standard type system alongside linearity and graded types, and extend Granule accordingly with these ideas. less
Verifying Programs with Logic and Extended Proof Rules: Deep Embedding v.s. Shallow Embedding
0upvotes
By: Zhongye Wang, Qinxiang Cao, Yichen Tao
Many foundational program verification tools have been developed to build machine-checked program correctness proofs, a majority of which are based on Hoare logic. Their program logics, their assertion languages, and their underlying programming languages can be formalized by either a shallow embedding or a deep embedding. Tools like Iris and early versions of Verified Software Toolchain (VST) choose different shallow embeddings to formaliz... more
Many foundational program verification tools have been developed to build machine-checked program correctness proofs, a majority of which are based on Hoare logic. Their program logics, their assertion languages, and their underlying programming languages can be formalized by either a shallow embedding or a deep embedding. Tools like Iris and early versions of Verified Software Toolchain (VST) choose different shallow embeddings to formalize their program logics. But the pros and cons of these different embeddings were not yet well studied. Therefore, we want to study the impact of the program logic's embedding on logic's proof rules in this paper. This paper considers a set of useful extended proof rules, and four different logic embeddings: one deep embedding and three common shallow embeddings. We prove the validity of these extended rules under these embeddings and discuss their main challenges. Furthermore, we propose a method to lift existing shallowly embedded logics to deeply embedded ones to greatly simplify proofs of extended rules in specific proof systems. We evaluate our results on two existing verification tools. We lift the originally shallowly embedded VST to our deeply embedded VST to support extended rules, and we implement Iris-CF and deeply embedded Iris-Imp based on the Iris framework to evaluate our theory in real verification projects. less
By: Simmo Saan, Michael Schwarz, Julian Erhard, Helmut Seidl, Sarah Tilscher, Vesal Vojdani
Witnesses record automated program analysis results and make them exchangeable. To validate correctness witnesses through abstract interpretation, we introduce a novel abstract operation unassume. This operator incorporates witness invariants into the abstract program state. Given suitable invariants, the unassume operation can accelerate fixpoint convergence and yield more precise results. We demonstrate the feasibility of this approach by... more
Witnesses record automated program analysis results and make them exchangeable. To validate correctness witnesses through abstract interpretation, we introduce a novel abstract operation unassume. This operator incorporates witness invariants into the abstract program state. Given suitable invariants, the unassume operation can accelerate fixpoint convergence and yield more precise results. We demonstrate the feasibility of this approach by augmenting an abstract interpreter with unassume operators and evaluating the impact of incorporating witnesses on performance and precision. Using manually crafted witnesses, we can confirm verification results for multi-threaded programs with a reduction in effort ranging from 7% to 47% in CPU time. More intriguingly, we discover that using witnesses from model checkers can guide our analyzer to verify program properties that it could not verify on its own. less
By: Xun An
An important dimension of pointer analysis is field-Sensitive, which has been proven to effectively enhance the accuracy of pointer analysis results. A crucial area of research within field-Sensitive is Structure-Sensitive. Structure-Sensitive has been shown to further enhance the precision of pointer analysis. However, existing structure-sensitive methods cannot handle cases where an object possesses multiple structures, even though it's c... more
An important dimension of pointer analysis is field-Sensitive, which has been proven to effectively enhance the accuracy of pointer analysis results. A crucial area of research within field-Sensitive is Structure-Sensitive. Structure-Sensitive has been shown to further enhance the precision of pointer analysis. However, existing structure-sensitive methods cannot handle cases where an object possesses multiple structures, even though it's common for an object to have multiple structures throughout its lifecycle. This paper introduces MTO-SS, a flow-sensitive pointer analysis method for objects with multiple structures. Our observation is that it's common for an object to possess multiple structures throughout its lifecycle. The novelty of MTO-SS lies in: MTO-SS introduces Structure-Flow-Sensitive. An object has different structure information at different locations in the program. To ensure the completeness of an object's structure information, MTO-SS always performs weak updates on the object's type. This means that once an object possesses a structure, this structure will accompany the object throughout its lifecycle. We evaluated our method of multi-structured object pointer analysis using the 12 largest programs in GNU Coreutils and compared the experimental results with sparse flow-sensitive method and another method, TYPECLONE, which only allows an object to have one structure information. Our experimental results confirm that MTO-SS is more precise than both sparse flow-sensitive pointer analysis and TYPECLONE, being able to answer, on average, over 22\% more alias queries with a no-alias result compared to the former, and over 3\% more compared to the latter. Additionally, the time overhead introduced by our method is very low. less
By: Zhendong Ang, Umang Mathur
In this paper, we focus on the problem of dynamically analysing concurrent software against high-level temporal specifications. Existing techniques for runtime monitoring against such specifications are primarily designed for sequential software and remain inadequate in the presence of concurrency -- violations may be observed only in intricate thread interleavings, requiring many re-runs of the underlying software. Towards this, we study t... more
In this paper, we focus on the problem of dynamically analysing concurrent software against high-level temporal specifications. Existing techniques for runtime monitoring against such specifications are primarily designed for sequential software and remain inadequate in the presence of concurrency -- violations may be observed only in intricate thread interleavings, requiring many re-runs of the underlying software. Towards this, we study the problem of predictive runtime monitoring, inspired by the analogous problem of predictive data race detection studied extensively recently. The predictive runtime monitoring question asks, given an execution $\sigma$, if it can be soundly reordered to expose violations of a specification. In this paper, we focus on specifications that are given in regular languages. Our notion of reorderings is trace equivalence, where an execution is considered a reordering of another if it can be obtained from the latter by successively commuting adjacent independent actions. We first show that the problem of predictive admits a super-linear lower bound of $O(n^\alpha)$, where $n$ is the number of events in the execution, and $\alpha$ is a parameter describing the degree of commutativity. As a result, predictive runtime monitoring even in this setting is unlikely to be efficiently solvable. Towards this, we identify a sub-class of regular languages, called pattern languages (and their extension generalized pattern languages). Pattern languages can naturally express specific ordering of some number of (labelled) events, and have been inspired by popular empirical hypotheses, the `small bug depth' hypothesis. More importantly, we show that for pattern (and generalized pattern) languages, the predictive monitoring problem can be solved using a constant-space streaming linear-time algorithm. less
By: Théo Laurent, Meven Lennon-Bertrand, Kenji Maillard
Dependently-typed proof assistant rely crucially on definitional equality, which relates types and terms that are automatically identified in the underlying type theory. This paper extends type theory with definitional functor laws, equations satisfied propositionally by a large class of container-like type constructors $F : \operatorname{Type} \to \operatorname{Type}$, equipped with a $\operatorname{map}_{F} : (A \to B) \to F\ A \to F\ B$,... more
Dependently-typed proof assistant rely crucially on definitional equality, which relates types and terms that are automatically identified in the underlying type theory. This paper extends type theory with definitional functor laws, equations satisfied propositionally by a large class of container-like type constructors $F : \operatorname{Type} \to \operatorname{Type}$, equipped with a $\operatorname{map}_{F} : (A \to B) \to F\ A \to F\ B$, such as lists or trees. Promoting these equations to definitional ones strengthen the theory, enabling slicker proofs and more automation for functorial type constructors. This extension is used to modularly justify a structural form of coercive subtyping, propagating subtyping through type formers in a map-like fashion. We show that the resulting notion of coercive subtyping, thanks to the extra definitional equations, is equivalent to a natural and implicit form of subsumptive subtyping. The key result of decidability of type-checking in a dependent type system with functor laws for lists has been entirely mechanized in Coq. less
By: Guillaume Allais
In typed functional languages, one can typically only manipulate data in a type-safe manner if it first has been deserialised into an in-memory tree represented as a graph of nodes-as-structs and subterms-as-pointers. We demonstrate how we can use QTT as implemented in \idris{} to define a small universe of serialised datatypes, and provide generic programs allowing users to process values stored contiguously in buffers. Our approach al... more
In typed functional languages, one can typically only manipulate data in a type-safe manner if it first has been deserialised into an in-memory tree represented as a graph of nodes-as-structs and subterms-as-pointers. We demonstrate how we can use QTT as implemented in \idris{} to define a small universe of serialised datatypes, and provide generic programs allowing users to process values stored contiguously in buffers. Our approach allows implementors to prove the full functional correctness by construction of the IO functions processing the data stored in the buffer. less
A R4RS Compliant REPL in 7 KB
0upvotes
By: Léonard Oest O'Leary, Mathis Laroche, Marc Feeley
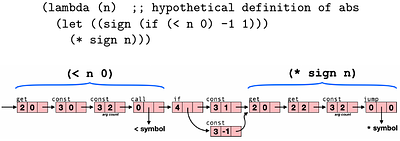
The Ribbit system is a compact Scheme implementation running on the Ribbit Virtual Machine (RVM) that has been ported to a dozen host languages. It supports a simple Foreign Function Interface (FFI) allowing extensions to the RVM directly from the program's source code. We have extended the system to offer conformance to the R4RS standard while staying as compact as possible. This leads to a R4RS compliant REPL that fits in an 7 KB Linux ex... more
The Ribbit system is a compact Scheme implementation running on the Ribbit Virtual Machine (RVM) that has been ported to a dozen host languages. It supports a simple Foreign Function Interface (FFI) allowing extensions to the RVM directly from the program's source code. We have extended the system to offer conformance to the R4RS standard while staying as compact as possible. This leads to a R4RS compliant REPL that fits in an 7 KB Linux executable. This paper explains the various issues encountered and our solutions to make, arguably, the smallest R4RS conformant Scheme implementation of all time. less
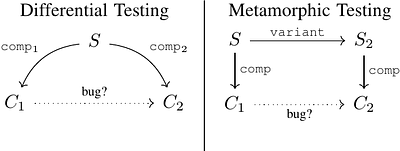
By: Luke Geeson, Lee Smith
It is critical that compilers are correct! Finding bugs is one aspect of testing the correctness of compilers in wide use today. A compiler is correct if every compiled program behaves as allowed by the semantics of its source code - else there is a bug. Memory consistency models define the semantics of concurrent programs. We focus on how to detect concurrency bugs introduced by compilers, as identified using memory models. We seek a testi... more
It is critical that compilers are correct! Finding bugs is one aspect of testing the correctness of compilers in wide use today. A compiler is correct if every compiled program behaves as allowed by the semantics of its source code - else there is a bug. Memory consistency models define the semantics of concurrent programs. We focus on how to detect concurrency bugs introduced by compilers, as identified using memory models. We seek a testing technique that automatically covers concurrency bugs up to fixed bounds on program sizes and that scales to find bugs in compiled programs with many lines of code. Otherwise, a testing technique can miss bugs. Unfortunately, the state-of-the-art techniques are yet to satisfy all of these properties. We present the T\'el\'echat compiler testing tool for concurrent programs. T\'el\'echat finds a concurrency bug when the behaviour of a compiled program, as allowed by its architecture memory model, is not a behaviour of the source program under its source model. We make three claims: T\'el\'echat improves the state-of-the-art at finding bugs in code generation for multi-threaded execution, it is the first public description of a compiler testing tool for concurrency that is deployed in industry, and it is the first tool that takes a significant step towards the desired properties. We provide experimental evidence suggesting T\'el\'echat finds bugs missed by other state-of-the-art techniques, case studies indicating that T\'el\'echat satisfies the properties, and reports of our experience deploying T\'el\'echat in industry. less