By: Kamil Akesbi, Dorian Desblancs, Benjamin Martin
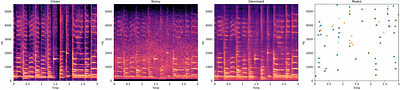
Audio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by ... more
Audio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by introducing and releasing a new audio augmentation pipeline that adds noise to music snippets in a realistic way, by stochastically mimicking real-world scenarios. We then propose and release a deep learning model that removes noisy components from spectrograms in order to improve peak-based fingerprinting systems' accuracy. We show that the addition of our model improves the identification performance of commonly used audio fingerprinting systems, even under noisy conditions. less
By: Donghuo Zeng, Kazushi Ikeda
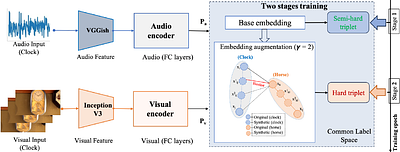
The cross-modal retrieval model leverages the potential of triple loss optimization to learn robust embedding spaces. However, existing methods often train these models in a singular pass, overlooking the distinction between semi-hard and hard triples in the optimization process. The oversight of not distinguishing between semi-hard and hard triples leads to suboptimal model performance. In this paper, we introduce a novel approach rooted i... more
The cross-modal retrieval model leverages the potential of triple loss optimization to learn robust embedding spaces. However, existing methods often train these models in a singular pass, overlooking the distinction between semi-hard and hard triples in the optimization process. The oversight of not distinguishing between semi-hard and hard triples leads to suboptimal model performance. In this paper, we introduce a novel approach rooted in curriculum learning to address this problem. We propose a two-stage training paradigm that guides the model's learning process from semi-hard to hard triplets. In the first stage, the model is trained with a set of semi-hard triplets, starting from a low-loss base. Subsequently, in the second stage, we augment the embeddings using an interpolation technique. This process identifies potential hard negatives, alleviating issues arising from high-loss functions due to a scarcity of hard triples. Our approach then applies hard triplet mining in the augmented embedding space to further optimize the model. Extensive experimental results conducted on two audio-visual datasets show a significant improvement of approximately 9.8% in terms of average Mean Average Precision (MAP) over the current state-of-the-art method, MSNSCA, for the Audio-Visual Cross-Modal Retrieval (AV-CMR) task on the AVE dataset, indicating the effectiveness of our proposed method. less
By: Wanli Sun, Zehai Tu, Anton Ragni
Recently there has been a lot of interest in non-autoregressive (non-AR) models for speech synthesis, such as FastSpeech 2 and diffusion models. Unlike AR models, these models do not have autoregressive dependencies among outputs which makes inference efficient. This paper expands the range of available non-AR models with another member called energy-based models (EBMs). The paper describes how noise contrastive estimation, which relies on ... more
Recently there has been a lot of interest in non-autoregressive (non-AR) models for speech synthesis, such as FastSpeech 2 and diffusion models. Unlike AR models, these models do not have autoregressive dependencies among outputs which makes inference efficient. This paper expands the range of available non-AR models with another member called energy-based models (EBMs). The paper describes how noise contrastive estimation, which relies on the comparison between positive and negative samples, can be used to train EBMs. It proposes a number of strategies for generating effective negative samples, including using high-performing AR models. It also describes how sampling from EBMs can be performed using Langevin Markov Chain Monte-Carlo (MCMC). The use of Langevin MCMC enables to draw connections between EBMs and currently popular diffusion models. Experiments on LJSpeech dataset show that the proposed approach offers improvements over Tacotron 2. less
By: Hanan Hamza, Fiza Gafoor, Fathima Sithara, Gayathri Anil, V. S. Anoop
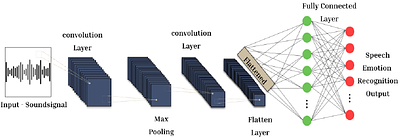
In the era of advanced artificial intelligence and human-computer interaction, identifying emotions in spoken language is paramount. This research explores the integration of deep learning techniques in speech emotion recognition, offering a comprehensive solution to the challenges associated with speaker diarization and emotion identification. It introduces a framework that combines a pre-existing speaker diarization pipeline and an emotio... more
In the era of advanced artificial intelligence and human-computer interaction, identifying emotions in spoken language is paramount. This research explores the integration of deep learning techniques in speech emotion recognition, offering a comprehensive solution to the challenges associated with speaker diarization and emotion identification. It introduces a framework that combines a pre-existing speaker diarization pipeline and an emotion identification model built on a Convolutional Neural Network (CNN) to achieve higher precision. The proposed model was trained on data from five speech emotion datasets, namely, RAVDESS, CREMA-D, SAVEE, TESS, and Movie Clips, out of which the latter is a speech emotion dataset created specifically for this research. The features extracted from each sample include Mel Frequency Cepstral Coefficients (MFCC), Zero Crossing Rate (ZCR), Root Mean Square (RMS), and various data augmentation algorithms like pitch, noise, stretch, and shift. This feature extraction approach aims to enhance prediction accuracy while reducing computational complexity. The proposed model yields an unweighted accuracy of 63%, demonstrating remarkable efficiency in accurately identifying emotional states within speech signals. less
By: Han Zhang, Rayehe Karimi Mahabadi, Cynthia Rudin, Johann Guilleminot, L. Catherine Brinson
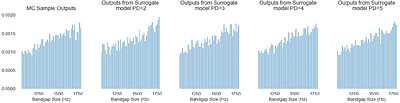
This paper studies the utility of techniques within uncertainty quantification, namely spectral projection and polynomial chaos expansion, in reducing sampling needs for characterizing acoustic metamaterial dispersion band responses given stochastic material properties and geometric defects. A novel method of encoding geometric defects in an interpretable, resolution independent is showcased in the formation of input space probability distr... more
This paper studies the utility of techniques within uncertainty quantification, namely spectral projection and polynomial chaos expansion, in reducing sampling needs for characterizing acoustic metamaterial dispersion band responses given stochastic material properties and geometric defects. A novel method of encoding geometric defects in an interpretable, resolution independent is showcased in the formation of input space probability distributions. Orders of magnitude sampling reductions down to $\sim10^0$ and $\sim10^1$ are achieved in the 1D and 7D input space scenarios respectively while maintaining accurate output space probability distributions through combining Monte Carlo, quadrature rule, and sparse grid sampling with surrogate model fitting. less
By: Kazuya Yokota, Takahiko Kurahashi, Masajiro Abe
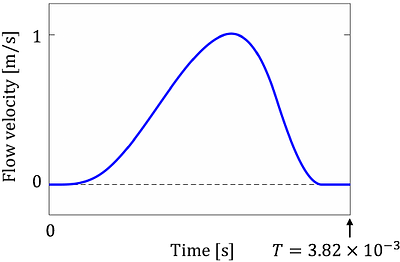
This study proposes the physics-informed neural network (PINN) framework to solve the wave equation for acoustic resonance analysis. ResoNet, the analytical model proposed in this study, minimizes the loss function for periodic solutions, in addition to conventional PINN loss functions, thereby effectively using the function approximation capability of neural networks, while performing resonance analysis. Additionally, it can be easily appl... more
This study proposes the physics-informed neural network (PINN) framework to solve the wave equation for acoustic resonance analysis. ResoNet, the analytical model proposed in this study, minimizes the loss function for periodic solutions, in addition to conventional PINN loss functions, thereby effectively using the function approximation capability of neural networks, while performing resonance analysis. Additionally, it can be easily applied to inverse problems. Herein, the resonance in a one-dimensional acoustic tube was analyzed. The effectiveness of the proposed method was validated through the forward and inverse analyses of the wave equation with energy-loss terms. In the forward analysis, the applicability of PINN to the resonance problem was evaluated by comparison with the finite-difference method. The inverse analysis, which included the identification of the energy loss term in the wave equation and design optimization of the acoustic tube, was performed with good accuracy. less
By: Kari A Noriy, Xiaosong Yang, Marcin Budka, Jian Jun Zhang
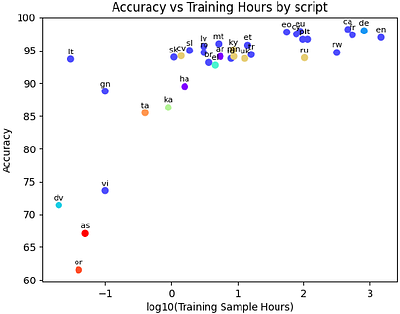
This paper proposes a novel framework for multilingual speech and sound representation learning using contrastive learning. The lack of sizeable labelled datasets hinders speech-processing research across languages. Recent advances in contrastive learning provide self-supervised techniques to learn from unlabelled data. Motivated by reducing data dependence and improving generalisation across diverse languages and conditions, we develop a m... more
This paper proposes a novel framework for multilingual speech and sound representation learning using contrastive learning. The lack of sizeable labelled datasets hinders speech-processing research across languages. Recent advances in contrastive learning provide self-supervised techniques to learn from unlabelled data. Motivated by reducing data dependence and improving generalisation across diverse languages and conditions, we develop a multilingual contrastive framework. This framework enables models to acquire shared representations across languages, facilitating cross-lingual transfer with limited target language data. Additionally, capturing emotional cues within speech is challenging due to subjective perceptual assessments. By learning expressive representations from diverse, multilingual data in a self-supervised manner, our approach aims to develop speech representations that encode emotive dimensions. Our method trains encoders on a large corpus of multi-lingual audio data. Data augmentation techniques are employed to expand the dataset. The contrastive learning approach trains the model to maximise agreement between positive pairs and minimise agreement between negative pairs. Extensive experiments demonstrate state-of-the-art performance of the proposed model on emotion recognition, audio classification, and retrieval benchmarks under zero-shot and few-shot conditions. This provides an effective approach for acquiring shared and generalised speech representations across languages and acoustic conditions while encoding latent emotional dimensions. less
BUT CHiME-7 system description
0upvotes
By: Martin Karafiát, Karel Veselý, Igor Szöke, Ladislav Mošner, Karel Beneš, Marcin Witkowski, Germán Barchi, Leonardo Pepino
This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from m... more
This paper describes the joint effort of Brno University of Technology (BUT), AGH University of Krakow and University of Buenos Aires on the development of Automatic Speech Recognition systems for the CHiME-7 Challenge. We train and evaluate various end-to-end models with several toolkits. We heavily relied on Guided Source Separation (GSS) to convert multi-channel audio to single channel. The ASR is leveraging speech representations from models pre-trained by self-supervised learning, and we do a fusion of several ASR systems. In addition, we modified external data from the LibriSpeech corpus to become a close domain and added it to the training. Our efforts were focused on the far-field acoustic robustness sub-track of Task 1 - Distant Automatic Speech Recognition (DASR), our systems use oracle segmentation. less
By: Yixiao Zhang, Akira Maezawa, Gus Xia, Kazuhiko Yamamoto, Simon Dixon
Creating music is iterative, requiring varied methods at each stage. However, existing AI music systems fall short in orchestrating multiple subsystems for diverse needs. To address this gap, we introduce Loop Copilot, a novel system that enables users to generate and iteratively refine music through an interactive, multi-round dialogue interface. The system uses a large language model to interpret user intentions and select appropriate AI ... more
Creating music is iterative, requiring varied methods at each stage. However, existing AI music systems fall short in orchestrating multiple subsystems for diverse needs. To address this gap, we introduce Loop Copilot, a novel system that enables users to generate and iteratively refine music through an interactive, multi-round dialogue interface. The system uses a large language model to interpret user intentions and select appropriate AI models for task execution. Each backend model is specialized for a specific task, and their outputs are aggregated to meet the user's requirements. To ensure musical coherence, essential attributes are maintained in a centralized table. We evaluate the effectiveness of the proposed system through semi-structured interviews and questionnaires, highlighting its utility not only in facilitating music creation but also its potential for broader applications. less
BeatDance: A Beat-Based Model-Agnostic Contrastive Learning Framework for Music-Dance Retrieval
0upvotes
By: Kaixing Yang, Xukun Zhou, Xulong Tang, Ran Diao, Hongyan Liu, Jun He, Zhaoxin Fan
Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. B... more
Dance and music are closely related forms of expression, with mutual retrieval between dance videos and music being a fundamental task in various fields like education, art, and sports. However, existing methods often suffer from unnatural generation effects or fail to fully explore the correlation between music and dance. To overcome these challenges, we propose BeatDance, a novel beat-based model-agnostic contrastive learning framework. BeatDance incorporates a Beat-Aware Music-Dance InfoExtractor, a Trans-Temporal Beat Blender, and a Beat-Enhanced Hubness Reducer to improve dance-music retrieval performance by utilizing the alignment between music beats and dance movements. We also introduce the Music-Dance (MD) dataset, a large-scale collection of over 10,000 music-dance video pairs for training and testing. Experimental results on the MD dataset demonstrate the superiority of our method over existing baselines, achieving state-of-the-art performance. The code and dataset will be made public available upon acceptance. less