EmoDiarize: Speaker Diarization and Emotion Identification from Speech Signals using Convolutional Neural Networks
EmoDiarize: Speaker Diarization and Emotion Identification from Speech Signals using Convolutional Neural Networks
Hanan Hamza, Fiza Gafoor, Fathima Sithara, Gayathri Anil, V. S. Anoop
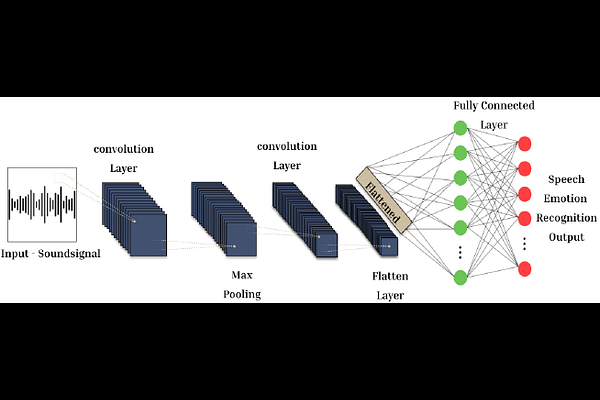
AbstractIn the era of advanced artificial intelligence and human-computer interaction, identifying emotions in spoken language is paramount. This research explores the integration of deep learning techniques in speech emotion recognition, offering a comprehensive solution to the challenges associated with speaker diarization and emotion identification. It introduces a framework that combines a pre-existing speaker diarization pipeline and an emotion identification model built on a Convolutional Neural Network (CNN) to achieve higher precision. The proposed model was trained on data from five speech emotion datasets, namely, RAVDESS, CREMA-D, SAVEE, TESS, and Movie Clips, out of which the latter is a speech emotion dataset created specifically for this research. The features extracted from each sample include Mel Frequency Cepstral Coefficients (MFCC), Zero Crossing Rate (ZCR), Root Mean Square (RMS), and various data augmentation algorithms like pitch, noise, stretch, and shift. This feature extraction approach aims to enhance prediction accuracy while reducing computational complexity. The proposed model yields an unweighted accuracy of 63%, demonstrating remarkable efficiency in accurately identifying emotional states within speech signals.