Music Augmentation and Denoising For Peak-Based Audio Fingerprinting
Music Augmentation and Denoising For Peak-Based Audio Fingerprinting
Kamil Akesbi, Dorian Desblancs, Benjamin Martin
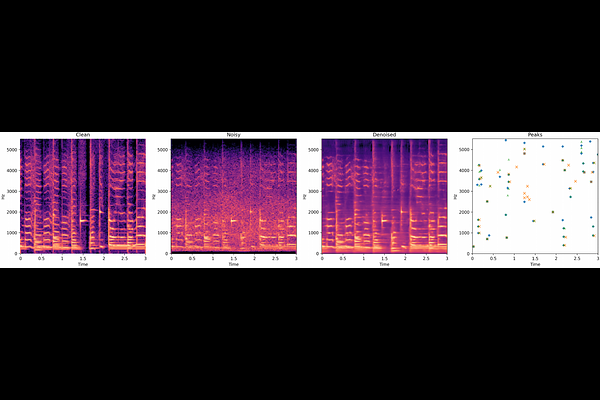
AbstractAudio fingerprinting is a well-established solution for song identification from short recording excerpts. Popular methods rely on the extraction of sparse representations, generally spectral peaks, and have proven to be accurate, fast, and scalable to large collections. However, real-world applications of audio identification often happen in noisy environments, which can cause these systems to fail. In this work, we tackle this problem by introducing and releasing a new audio augmentation pipeline that adds noise to music snippets in a realistic way, by stochastically mimicking real-world scenarios. We then propose and release a deep learning model that removes noisy components from spectrograms in order to improve peak-based fingerprinting systems' accuracy. We show that the addition of our model improves the identification performance of commonly used audio fingerprinting systems, even under noisy conditions.