An Energy-Efficient Near-Data Processing Accelerator for DNNs that Optimizes Data Accesses
An Energy-Efficient Near-Data Processing Accelerator for DNNs that Optimizes Data Accesses
Bahareh Khabbazan, Marc Riera, Antonio González
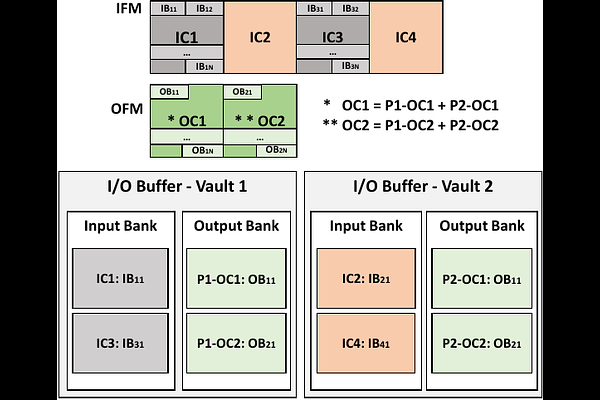
AbstractThe constant growth of DNNs makes them challenging to implement and run efficiently on traditional compute-centric architectures. Some accelerators have attempted to add more compute units and on-chip buffers to solve the memory wall problem without much success, and sometimes even worsening the issue since more compute units also require higher memory bandwidth. Prior works have proposed the design of memory-centric architectures based on the Near-Data Processing (NDP) paradigm. NDP seeks to break the memory wall by moving the computations closer to the memory hierarchy, reducing the data movements and their cost as much as possible. The 3D-stacked memory is especially appealing for DNN accelerators due to its high-density/low-energy storage and near-memory computation capabilities to perform the DNN operations massively in parallel. However, memory accesses remain as the main bottleneck for running modern DNNs efficiently. To improve the efficiency of DNN inference we present QeiHaN, a hardware accelerator that implements a 3D-stacked memory-centric weight storage scheme to take advantage of a logarithmic quantization of activations. In particular, since activations of FC and CONV layers of modern DNNs are commonly represented as powers of two with negative exponents, QeiHaN performs an implicit in-memory bit-shifting of the DNN weights to reduce memory activity. Only the meaningful bits of the weights required for the bit-shift operation are accessed. Overall, QeiHaN reduces memory accesses by 25\% compared to a standard memory organization. We evaluate QeiHaN on a popular set of DNNs. On average, QeiHaN provides $4.3x$ speedup and $3.5x$ energy savings over a Neurocube-like accelerator.