Python is widely used in the open-source community, largely owing to the extensive support from diverse third-party libraries within the PyPI ecosystem. Nevertheless, the utilization of third-party libraries can potentially lead to conflicts in dependencies, prompting researchers to develop dependency conflict detectors. Moreover, endeavors have been made to automatically infer dependencies. These approaches focus on version-level checks an...
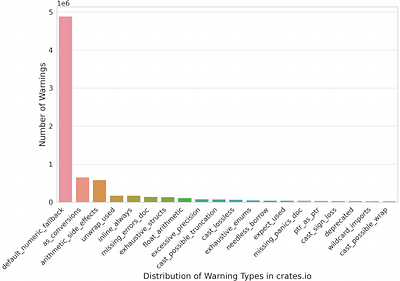
more Python is widely used in the open-source community, largely owing to the extensive support from diverse third-party libraries within the PyPI ecosystem. Nevertheless, the utilization of third-party libraries can potentially lead to conflicts in dependencies, prompting researchers to develop dependency conflict detectors. Moreover, endeavors have been made to automatically infer dependencies. These approaches focus on version-level checks and inference, based on the assumption that configurations of libraries in the PyPI ecosystem are correct. However, our study reveals that this assumption is not universally valid, and relying solely on version-level checks proves inadequate in ensuring compatible run-time environments. In this paper, we conduct an empirical study to comprehensively study the configuration issues in the PyPI ecosystem. Specifically, we propose PyCon, a source-level detector, for detecting potential configuration issues. PyCon employs three distinct checks, targeting the setup, packing, and usage stages of libraries, respectively. To evaluate the effectiveness of the current automatic dependency inference approaches, we build a benchmark called VLibs, comprising library releases that pass all three checks of PyCon. We identify 15 kinds of configuration issues and find that 183,864 library releases suffer from potential configuration issues. Remarkably, 68% of these issues can only be detected via the source-level check. Our experiment results show that the most advanced automatic dependency inference approach, PyEGo, can successfully infer dependencies for only 65% of library releases. The primary failures stem from dependency conflicts and the absence of required libraries in the generated configurations. Based on the empirical results, we derive six findings and draw two implications for open-source developers and future research in automatic dependency inference.
less