By: Bowen Zheng, Ran Cheng, Kay Chen Tan
Evolutionary Reinforcement Learning (EvoRL) has emerged as a promising approach to overcoming the limitations of traditional reinforcement learning (RL) by integrating the Evolutionary Computation (EC) paradigm with RL. However, the population-based nature of EC significantly increases computational costs, thereby restricting the exploration of algorithmic design choices and scalability in large-scale settings. To address this challenge, we... more
Evolutionary Reinforcement Learning (EvoRL) has emerged as a promising approach to overcoming the limitations of traditional reinforcement learning (RL) by integrating the Evolutionary Computation (EC) paradigm with RL. However, the population-based nature of EC significantly increases computational costs, thereby restricting the exploration of algorithmic design choices and scalability in large-scale settings. To address this challenge, we introduce $\texttt{$\textbf{EvoRL}$}$, the first end-to-end EvoRL framework optimized for GPU acceleration. The framework executes the entire training pipeline on accelerators, including environment simulations and EC processes, leveraging hierarchical parallelism through vectorization and compilation techniques to achieve superior speed and scalability. This design enables the efficient training of large populations on a single machine. In addition to its performance-oriented design, $\texttt{$\textbf{EvoRL}$}$ offers a comprehensive platform for EvoRL research, encompassing implementations of traditional RL algorithms (e.g., A2C, PPO, DDPG, TD3, SAC), Evolutionary Algorithms (e.g., CMA-ES, OpenES, ARS), and hybrid EvoRL paradigms such as Evolutionary-guided RL (e.g., ERL, CEM-RL) and Population-Based AutoRL (e.g., PBT). The framework's modular architecture and user-friendly interface allow researchers to seamlessly integrate new components, customize algorithms, and conduct fair benchmarking and ablation studies. The project is open-source and available at: https://github.com/EMI-Group/evorl. less
6 SciCasts by .
By: Maria Laura Santoni, Christoph Dürr, Carola Doerr, Mike Preuss, Elena Raponi
Rather than obtaining a single good solution for a given optimization problem, users often seek alternative design choices, because the best-found solution may perform poorly with respect to additional objectives or constraints that are difficult to capture into the modeling process. Aiming for batches of diverse solutions of high quality is often desirable, as it provides flexibility to accommodate post-hoc user preferences. At the same ... more
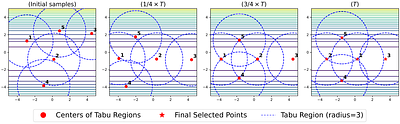
Rather than obtaining a single good solution for a given optimization problem, users often seek alternative design choices, because the best-found solution may perform poorly with respect to additional objectives or constraints that are difficult to capture into the modeling process. Aiming for batches of diverse solutions of high quality is often desirable, as it provides flexibility to accommodate post-hoc user preferences. At the same time, it is crucial that the quality of the best solution found is not compromised. One particular problem setting balancing high quality and diversity is fixing the required minimum distance between solutions while simultaneously obtaining the best possible fitness. Recent work by Santoni et al. [arXiv 2024] revealed that this setting is not well addressed by state-of-the-art algorithms, performing in par or worse than pure random sampling. Driven by this important limitation, we propose a new approach, where parallel runs of the covariance matrix adaptation evolution strategy (CMA-ES) inherit tabu regions in a cascading fashion. We empirically demonstrate that our CMA-ES-Diversity Search (CMA-ES-DS) algorithm generates trajectories that allow to extract high-quality solution batches that respect a given minimum distance requirement, clearly outperforming those obtained from off-the-shelf random sampling, multi-modal optimization algorithms, and standard CMA-ES. less
By: Yuta Sekino, Kento Uchida, Shinichi Shirakawa
Several practical applications of evolutionary computation possess objective functions that receive the design variables and externally given parameters. Such problems are termed contextual optimization problems. These problems require finding the optimal solutions corresponding to the given context vectors. Existing contextual optimization methods train a policy model to predict the optimal solution from context vectors. However, the perfo... more
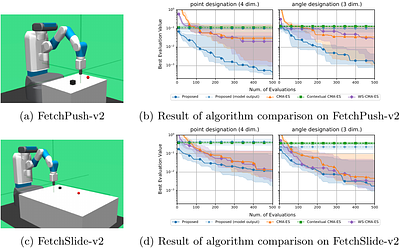
Several practical applications of evolutionary computation possess objective functions that receive the design variables and externally given parameters. Such problems are termed contextual optimization problems. These problems require finding the optimal solutions corresponding to the given context vectors. Existing contextual optimization methods train a policy model to predict the optimal solution from context vectors. However, the performance of such models is limited by their representation ability. By contrast, warm starting methods have been used to initialize evolutionary algorithms on a given problem using the optimization results on similar problems. Because warm starting methods do not consider the context vectors, their performances can be improved on contextual optimization problems. Herein, we propose a covariance matrix adaptation evolution strategy with contextual warm starting (CMA-ES-CWS) to efficiently optimize the contextual optimization problem with a given context vector. The CMA-ES-CWS utilizes the optimization results of past context vectors to train the multivariate Gaussian process regression. Subsequently, the CMA-ES-CWS performs warm starting for a given context vector by initializing the search distribution using posterior distribution of the Gaussian process regression. The results of the numerical simulation suggest that CMA-ES-CWS outperforms the existing contextual optimization and warm starting methods. less
By: Emil Njor, Colby Banbury, Xenofon Fafoutis
Tiny machine learning (TinyML) promises to revolutionize fields such as healthcare, environmental monitoring, and industrial maintenance by running machine learning models on low-power embedded systems. However, the complex optimizations required for successful TinyML deployment continue to impede its widespread adoption. A promising route to simplifying TinyML is through automatic machine learning (AutoML), which can distill elaborate opti... more
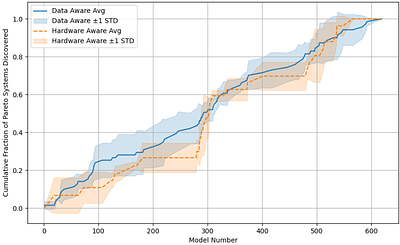
Tiny machine learning (TinyML) promises to revolutionize fields such as healthcare, environmental monitoring, and industrial maintenance by running machine learning models on low-power embedded systems. However, the complex optimizations required for successful TinyML deployment continue to impede its widespread adoption. A promising route to simplifying TinyML is through automatic machine learning (AutoML), which can distill elaborate optimization workflows into accessible key decisions. Notably, Hardware Aware Neural Architecture Searches - where a computer searches for an optimal TinyML model based on predictive performance and hardware metrics - have gained significant traction, producing some of today's most widely used TinyML models. Nevertheless, limiting optimization solely to neural network architectures can prove insufficient. Because TinyML systems must operate under extremely tight resource constraints, the choice of input data configuration, such as resolution or sampling rate, also profoundly impacts overall system efficiency. Achieving truly optimal TinyML systems thus requires jointly tuning both input data and model architecture. Despite its importance, this "Data Aware Neural Architecture Search" remains underexplored. To address this gap, we propose a new state-of-the-art Data Aware Neural Architecture Search technique and demonstrate its effectiveness on the novel TinyML ``Wake Vision'' dataset. Our experiments show that across varying time and hardware constraints, Data Aware Neural Architecture Search consistently discovers superior TinyML systems compared to purely architecture-focused methods, underscoring the critical role of data-aware optimization in advancing TinyML. less
By: Chenxiang Ma, Xinyi Chen, Yanchen Li, Qu Yang, Yujie Wu, Guoqi Li, Gang Pan, Huajin Tang, Kay Chen Tan, Jibin Wu
Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of thei... more
Temporal processing is fundamental for both biological and artificial intelligence systems, as it enables the comprehension of dynamic environments and facilitates timely responses. Spiking Neural Networks (SNNs) excel in handling such data with high efficiency, owing to their rich neuronal dynamics and sparse activity patterns. Given the recent surge in the development of SNNs, there is an urgent need for a comprehensive evaluation of their temporal processing capabilities. In this paper, we first conduct an in-depth assessment of commonly used neuromorphic benchmarks, revealing critical limitations in their ability to evaluate the temporal processing capabilities of SNNs. To bridge this gap, we further introduce a benchmark suite consisting of three temporal processing tasks characterized by rich temporal dynamics across multiple timescales. Utilizing this benchmark suite, we perform a thorough evaluation of recently introduced SNN approaches to elucidate the current status of SNNs in temporal processing. Our findings indicate significant advancements in recently developed spiking neuron models and neural architectures regarding their temporal processing capabilities, while also highlighting a performance gap in handling long-range dependencies when compared to state-of-the-art non-spiking models. Finally, we discuss the key challenges and outline potential avenues for future research. less