Optimization-Free Topological Sort for Causal Discovery via the Schur Complement of Score Jacobians
0upvotes
By: Rui Wu, Hong Xie
Continuous causal discovery typically couples representation learning with structural optimization via non-convex acyclicity penalties, which subjects solvers to local optima and restricts scalability in high-dimensional regimes. We propose a decoupled paradigm that shifts the causal discovery bottleneck from non-convex optimization to statistical score estimation. We introduce the Score-Schur Topological Sort (SSTS), an algorithm that extrac... more
Continuous causal discovery typically couples representation learning with structural optimization via non-convex acyclicity penalties, which subjects solvers to local optima and restricts scalability in high-dimensional regimes. We propose a decoupled paradigm that shifts the causal discovery bottleneck from non-convex optimization to statistical score estimation. We introduce the Score-Schur Topological Sort (SSTS), an algorithm that extracts topological order directly from unconstrained generative models, bypassing constrained structure optimization. We establish that the causal hierarchy leaves a geometric signature within the score function: iterative graph marginalization is mathematically equivalent to computing the Schur complement of the Score-Jacobian Information Matrix (SJIM) under linear conditions. This translates the acyclicity constraint into an algebraic procedure with a dominant cost of O(d^3) operations. For non-linear systems, we formulate the expectation gap of Schur marginalization and introduce Block-SSTS to compress extraction depth, bounding structural error. Empirically, SSTS allows causal structural analysis on non-linear graphs up to d=1000. At this scale, our framework indicates that once the non-convex optimization bottleneck is mathematically bypassed, the structural fidelity of continuous causal discovery is bounded by the finite-sample estimation variance of the global score geometry. By reducing graph extraction to matrix operations, this work reframes scalable causal discovery from a constrained optimization problem to a statistical estimation challenge. less
5 SciCasts by .
By: Zhiyuan Fan, Tinghao Yu, Yuanjun Cai, Jiangtao Guan, Yun Yang, Dingxin Hu, Jiang Zhou, Xing Wu, Zhuo Han, Feng Zhang, Lilin Wang
Terminal agents have demonstrated strong potential for autonomous command-line execution, yet their training remains constrained by the scarcity of high-quality and diverse execution trajectories. Existing approaches mitigate this bottleneck by synthesizing large-scale terminal task instances for trajectory sampling. However, they primarily focus on scaling the number of tasks while providing limited control over the diversity of execution tr... more
Terminal agents have demonstrated strong potential for autonomous command-line execution, yet their training remains constrained by the scarcity of high-quality and diverse execution trajectories. Existing approaches mitigate this bottleneck by synthesizing large-scale terminal task instances for trajectory sampling. However, they primarily focus on scaling the number of tasks while providing limited control over the diversity of execution trajectories that agents actually experience during training. In this paper, we present SkillSynth, an automated framework for terminal task synthesis built on a scenario-mediated skill graph. SkillSynth first constructs a large-scale skill graph, where scenarios serve as intermediate transition nodes that connect diverse command-line skills. It then samples paths from this graph as abstractions of real-world workflows, and uses a multi-agent harness to instantiate them into executable task instances. By grounding task synthesis in graph-sampled workflow paths, SkillSynth explicitly controls the diversity of minimal execution trajectories required to solve the synthesized tasks. Experiments on Terminal-Bench demonstrate the effectiveness of SkillSynth. Moreover, task instances synthesized by SkillSynth have been adopted to train Hy3 Preview, contributing to its enhanced agentic capabilities in terminal-based settings. less

By: Zijian Guo, İlker Işık, H. M. Sabbir Ahmad, Wenchao Li
Specification-guided reinforcement learning (RL) provides a principled framework for encoding complex, temporally extended tasks using formal specifications such as linear temporal logic (LTL). While recent methods have shown promising results, their ability to generalize across unseen specifications and diverse environments remains insufficiently understood. In this work, we introduce SpecRLBench, a benchmark designed to evaluate the general... more
Specification-guided reinforcement learning (RL) provides a principled framework for encoding complex, temporally extended tasks using formal specifications such as linear temporal logic (LTL). While recent methods have shown promising results, their ability to generalize across unseen specifications and diverse environments remains insufficiently understood. In this work, we introduce SpecRLBench, a benchmark designed to evaluate the generalization capabilities of LTL-based specification-guided RL methods. The benchmark spans multiple difficulty levels across navigation and manipulation domains, incorporating both static and dynamic environments, diverse robot dynamics, and varied observation modalities. Through extensive empirical evaluation, we characterize the strengths and limitations of existing approaches and reveal the challenges that emerge as specification and environment complexity increase. SpecRLBench provides a structured platform for systematic comparison and supports the development of more generalizable specification-guided RL methods. Code is available at https://github.com/BU-DEPEND-Lab/SpecRLBench. less
By: Hailing Cheng, Tao Huang, Chen Zhu, Antonio Alonso
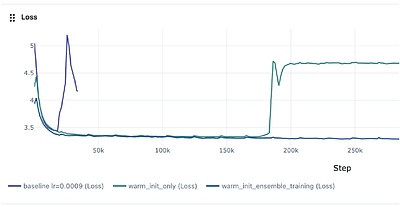
Training large neural networks with data-parallel stochastic gradient descent allocates N GPU replicas to compute effectively identical updates -- a practice that leaves the rich space of learning rate configurations entirely unexplored during training. We propose Hyperparameter-Divergent Ensemble Training (HDET), a method that repurposes these replicas for simultaneous learning rate exploration at negligible communication overhead. HDET oper... more
Training large neural networks with data-parallel stochastic gradient descent allocates N GPU replicas to compute effectively identical updates -- a practice that leaves the rich space of learning rate configurations entirely unexplored during training. We propose Hyperparameter-Divergent Ensemble Training (HDET), a method that repurposes these replicas for simultaneous learning rate exploration at negligible communication overhead. HDET operates in alternating phases: a fan-out stage in which replicas train independently under a structured, symmetric spread of learning rates, and a converge stage in which parameters are averaged across all replicas via AllReduce every T steps. Building on this ensemble substrate, we further propose an automatic learning rate (auto-LR) controller that treats the relative training loss across replicas as a performance signal, updating the shared base schedule toward higher-performing configurations via a momentum-based gradient-free meta-update. The combined method produces a self-adapting learning rate schedule that improves both optimization quality and generalization without additional hyperparameter sweeps or training budget. Crucially, the framework generalizes beyond learning rate: any scalar hyperparameter that does not alter model architecture -- such as dropout rate, attention scale temperature, or weight-decay coefficient -- can be explored across replicas using the same fan-out/converge protocol, with inter-replica loss differences serving as zero-order hypergradients that guide the search direction. HDET is implemented as a drop-in replacement for PyTorch's OneCycleLR scheduler, requiring no changes to model architecture, optimizer, or data pipeline. less
By: Chirag Pabbaraju
While the optimal sample complexity of binary classification in terms of the VC dimension is well-established, determining the optimal sample complexity of multiclass classification has remained open. The appropriate complexity parameter for multiclass classification is the DS dimension, and despite significant efforts, a gap of $\sqrt{\text{DS}}$ has persisted between the upper and lower bounds on sample complexity. Recent work by Hanneke ... more
While the optimal sample complexity of binary classification in terms of the VC dimension is well-established, determining the optimal sample complexity of multiclass classification has remained open. The appropriate complexity parameter for multiclass classification is the DS dimension, and despite significant efforts, a gap of $\sqrt{\text{DS}}$ has persisted between the upper and lower bounds on sample complexity. Recent work by Hanneke et al. (2026) shows a novel algebraic characterization of multiclass hypothesis classes in terms of their DS dimension. Building up on this, we show that the maximum hypergraph density of any multiclass hypothesis class is upper-bounded by its DS dimension. This proves a longstanding conjecture of Daniely and Shalev-Shwartz (2014). As a consequence, we determine the optimal dependence of the sample complexity on the DS dimension for multiclass as well as list learning. less
By: German Marin, Jatin Chaudhary
Autonomous AI agents can remain fully authorized and still become unsafe as behavior drifts, adversaries adapt, and decision patterns shift without any code change. We propose the \textbf{Informational Viability Principle}: governing an agent reduces to estimating a bound on unobserved risk $\hat{B}(x) = U(x) + SB(x) + RG(x)$ and allowing an action only when its capacity $S(x)$ exceeds $\hat{B}(x)$ by a safety margin. The \textbf{Agent Viabil... more
Autonomous AI agents can remain fully authorized and still become unsafe as behavior drifts, adversaries adapt, and decision patterns shift without any code change. We propose the \textbf{Informational Viability Principle}: governing an agent reduces to estimating a bound on unobserved risk $\hat{B}(x) = U(x) + SB(x) + RG(x)$ and allowing an action only when its capacity $S(x)$ exceeds $\hat{B}(x)$ by a safety margin. The \textbf{Agent Viability Framework}, grounded in Aubin's viability theory, establishes three properties -- monitoring (P1), anticipation (P2), and monotonic restriction (P3) -- as individually necessary and collectively sufficient for documented failure modes. \textbf{RiskGate} instantiates the framework with dedicated statistical estimators (KL divergence, segment-vs-rest $z$-tests, sequential pattern matching), a fail-secure monotonic pipeline, and a closed-loop Autopilot formalised as an instance of Aubin's regulation map with kill-switch-as-last-resort; a scalar Viability Index $VI(t) \in [-1,+1]$ with first-order $t^*$ prediction transforms governance from reactive to predictive. Contributions are the theoretical framework, the reference implementation, and analytical coverage against published agent-failure taxonomies; quantitative empirical evaluation is scoped as follow-up work. less