DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster
DiLoCoX: A Low-Communication Large-Scale Training Framework for Decentralized Cluster
Ji Qi, WenPeng Zhu, Li Li, Ming Wu, YingJun Wu, Wu He, Xun Gao, Jason Zeng, Michael Heinrich
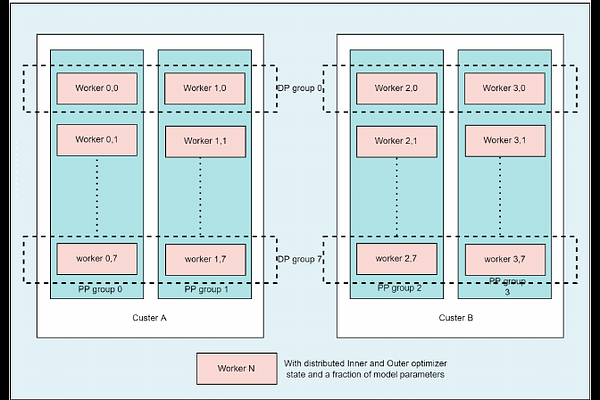
AbstractThe distributed training of foundation models, particularly large language models (LLMs), demands a high level of communication. Consequently, it is highly dependent on a centralized cluster with fast and reliable interconnects. Can we conduct training on slow networks and thereby unleash the power of decentralized clusters when dealing with models exceeding 100 billion parameters? In this paper, we propose DiLoCoX, a low-communication large-scale decentralized cluster training framework. It combines Pipeline Parallelism with Dual Optimizer Policy, One-Step-Delay Overlap of Communication and Local Training, and an Adaptive Gradient Compression Scheme. This combination significantly improves the scale of parameters and the speed of model pre-training. We justify the benefits of one-step-delay overlap of communication and local training, as well as the adaptive gradient compression scheme, through a theoretical analysis of convergence. Empirically, we demonstrate that DiLoCoX is capable of pre-training a 107B foundation model over a 1Gbps network. Compared to vanilla AllReduce, DiLoCoX can achieve a 357x speedup in distributed training while maintaining negligible degradation in model convergence. To the best of our knowledge, this is the first decentralized training framework successfully applied to models with over 100 billion parameters.