
By: Xu Tan, Jiawei Chen, Haohe Liu, Jian Cong, Chen Zhang, Yanqing Liu, Xi Wang, Yichong Leng, Yuanhao Yi, Lei He, Frank Soong, Tao Qin, Sheng Zhao, Tie-Yan Liu
Text to speech (TTS) has made rapid progress in both academia and industry in
recent years. Some questions naturally arise that whether a TTS system can
achieve human-level quality, how to define/judge that quality and how to
achieve it. In this paper, we answer these questions by first defining the
human-level quality based on the statistical significance of subjective measure
and introducing appropriate guidelines to judge it, and then de... more
Text to speech (TTS) has made rapid progress in both academia and industry in
recent years. Some questions naturally arise that whether a TTS system can
achieve human-level quality, how to define/judge that quality and how to
achieve it. In this paper, we answer these questions by first defining the
human-level quality based on the statistical significance of subjective measure
and introducing appropriate guidelines to judge it, and then developing a TTS
system called NaturalSpeech that achieves human-level quality on a benchmark
dataset. Specifically, we leverage a variational autoencoder (VAE) for
end-to-end text to waveform generation, with several key modules to enhance the
capacity of the prior from text and reduce the complexity of the posterior from
speech, including phoneme pre-training, differentiable duration modeling,
bidirectional prior/posterior modeling, and a memory mechanism in VAE.
Experiment evaluations on popular LJSpeech dataset show that our proposed
NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human
recordings at the sentence level, with Wilcoxon signed rank test at p-level p
>> 0.05, which demonstrates no statistically significant difference from human
recordings for the first time on this dataset.
less
By: Xu Tan, Jiawei Chen, Haohe Liu, Jian Cong, Chen Zhang, Yanqing Liu, Xi Wang, Yichong Leng, Yuanhao Yi, Lei He, Frank Soong, Tao Qin, Sheng Zhao, Tie-Yan Liu
Text to speech (TTS) has made rapid progress in both academia and industry in
recent years. Some questions naturally arise that whether a TTS system can
achieve human-level quality, how to define/judge that quality and how to
achieve it. In this paper, we answer these questions by first defining the
human-level quality based on the statistical significance of subjective measure
and introducing appropriate guidelines to judge it, and then de... more
Text to speech (TTS) has made rapid progress in both academia and industry in
recent years. Some questions naturally arise that whether a TTS system can
achieve human-level quality, how to define/judge that quality and how to
achieve it. In this paper, we answer these questions by first defining the
human-level quality based on the statistical significance of subjective measure
and introducing appropriate guidelines to judge it, and then developing a TTS
system called NaturalSpeech that achieves human-level quality on a benchmark
dataset. Specifically, we leverage a variational autoencoder (VAE) for
end-to-end text to waveform generation, with several key modules to enhance the
capacity of the prior from text and reduce the complexity of the posterior from
speech, including phoneme pre-training, differentiable duration modeling,
bidirectional prior/posterior modeling, and a memory mechanism in VAE.
Experiment evaluations on popular LJSpeech dataset show that our proposed
NaturalSpeech achieves -0.01 CMOS (comparative mean opinion score) to human
recordings at the sentence level, with Wilcoxon signed rank test at p-level p
>> 0.05, which demonstrates no statistically significant difference from human
recordings for the first time on this dataset.
less
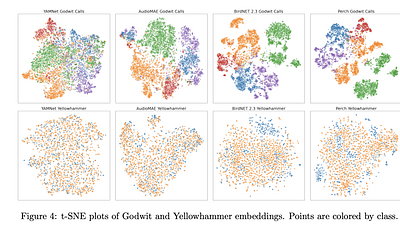
Feature Embeddings from Large-Scale Acoustic Bird Classifiers Enable Few-Shot Transfer Learning
1upvote
By: Burooj Ghani, Tom Denton, Stefan Kahl, Holger Klinck
Automated bioacoustic analysis aids understanding and protection of both
marine and terrestrial animals and their habitats across extensive
spatiotemporal scales, and typically involves analyzing vast collections of
acoustic data. With the advent of deep learning models, classification of
important signals from these datasets has markedly improved. These models power
critical data analyses for research and decision-making in biodiversity
mo... more
Automated bioacoustic analysis aids understanding and protection of both
marine and terrestrial animals and their habitats across extensive
spatiotemporal scales, and typically involves analyzing vast collections of
acoustic data. With the advent of deep learning models, classification of
important signals from these datasets has markedly improved. These models power
critical data analyses for research and decision-making in biodiversity
monitoring, animal behaviour studies, and natural resource management. However,
deep learning models are often data-hungry and require a significant amount of
labeled training data to perform well. While sufficient training data is
available for certain taxonomic groups (e.g., common bird species), many
classes (such as rare and endangered species, many non-bird taxa, and
call-type), lack enough data to train a robust model from scratch. This study
investigates the utility of feature embeddings extracted from large-scale audio
classification models to identify bioacoustic classes other than the ones these
models were originally trained on. We evaluate models on diverse datasets,
including different bird calls and dialect types, bat calls, marine mammals
calls, and amphibians calls. The embeddings extracted from the models trained
on bird vocalization data consistently allowed higher quality classification
than the embeddings trained on general audio datasets. The results of this
study indicate that high-quality feature embeddings from large-scale acoustic
bird classifiers can be harnessed for few-shot transfer learning, enabling the
learning of new classes from a limited quantity of training data. Our findings
reveal the potential for efficient analyses of novel bioacoustic tasks, even in
scenarios where available training data is limited to a few samples.
less
By: Eklavya Sarkar, RaviShankar Prasad, Mathew Magimai. -Doss
Voice activity detection (VAD) is an important pre-processing step for speech technology applications. The task consists of deriving segment boundaries of audio signals which contain voicing information. In recent years, it has been shown that voice source and vocal tract system information can be extracted using zero-frequency filtering (ZFF) without making any explicit model assumptions about the speech signal. This paper investigates the p... more
Voice activity detection (VAD) is an important pre-processing step for speech technology applications. The task consists of deriving segment boundaries of audio signals which contain voicing information. In recent years, it has been shown that voice source and vocal tract system information can be extracted using zero-frequency filtering (ZFF) without making any explicit model assumptions about the speech signal. This paper investigates the potential of zero-frequency filtering for jointly modeling voice source and vocal tract system information, and proposes two approaches for VAD. The first approach demarcates voiced regions using a composite signal composed of different zero-frequency filtered signals. The second approach feeds the composite signal as input to the rVAD algorithm. These approaches are compared with other supervised and unsupervised VAD methods in the literature, and are evaluated on the Aurora-2 database, across a range of SNRs (20 to -5 dB). Our studies show that the proposed ZFF-based methods perform comparable to state-of-art VAD methods and are more invariant to added degradation and different channel characteristics. less