GeST: Towards Building A Generative Pretrained Transformer for Learning Cellular Spatial Context
GeST: Towards Building A Generative Pretrained Transformer for Learning Cellular Spatial Context
Hao, M.; Yan, N.; Bian, H.; Chen, Y.; Gu, J.; Wei, L.; Zhang, X.
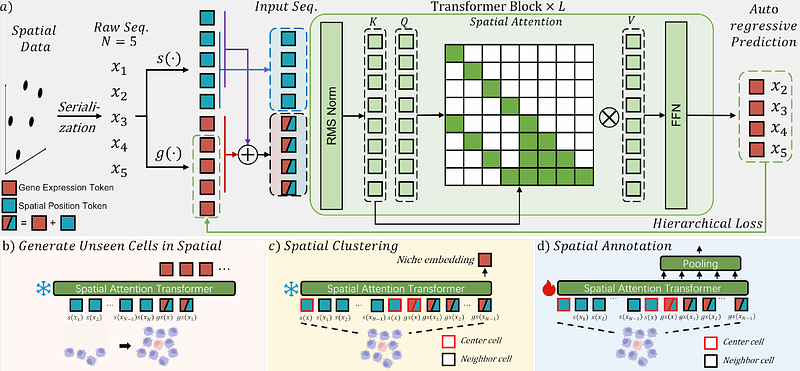
AbstractLearning spatial context of cells through pretraining on spatial transcriptomics (ST) data may empower us to systematically decipher tissue organization and cellular interactions. Yet, transformer-based generative models often focus on modeling individual cells, neglecting the intricate spatial relationships within them. We develop GeST, a deep transformer model that is pretrained by a novel spatially informed generation task: Predict cellular expression profile of a given location based on the information from its neighboring cells. We propose a spatial attention mechanism for efficient pretraining, a flexible serialization strategy for converting ST data into sequences, and a cell tokenization method for quantizing gene expression profiles. We pretrained GeST on large-scale ST datasets of different ST technologies and demonstrated its superior performance in generating unseen spatial cells. Our results also show that GeST can extract spatial niche embeddings in a zero-shot way and can be further fine-tuned for spatial annotation tasks. Furthermore, GeST can simulate gene expression changes in response to perturbations of cells within spatial context, closely matching existing experimental results. Overall, GeST offers a powerful generative pre-training framework for learning spatial contexts in spatial transcriptomics.