MolLM: Integrating 3D and 2D Molecular Representations with Biomedical Text via a Unified Pre-trained Language Model
MolLM: Integrating 3D and 2D Molecular Representations with Biomedical Text via a Unified Pre-trained Language Model
Tang, X.; Tran, A.; Tan, J.; Gerstein, M.
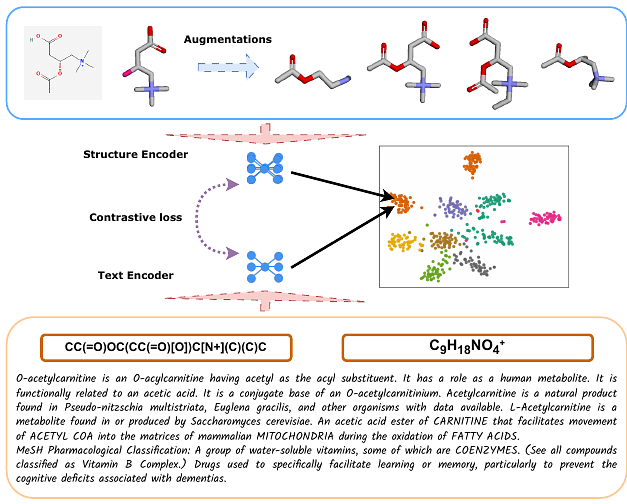
AbstractThe present paradigm of current deep learning models for molecular representation relies largely on singular 1D or 2D formats, neglecting significant 3D structural information that offers valuable physical insight. This narrow focus inhibits the model\'s versatility and adaptability across a wide range of modalities. Simultaneously, many of these models focus on deciphering the chemical structures of molecules, often overlooking the wealth of textual knowledge available in the field of chemistry and the biomedical domain. We present a unified pre-trained language model that concurrently captures biomedical text, 2D, and 3D molecular information, the three-modality Molecular Language Model (MolLM). Our model consists of a text Transformer encoder and a molecular Transformer encoder. Our approach employs contrastive learning as a supervisory signal for cross-modal information learning, and we assemble a multi-modality dataset using cheminformatics-based molecular modifications and a wealth of chemical text. MolLM demonstrates robust molecular representation capabilities in numerous downstream tasks, including cross-modality molecule and text matching, property prediction, captioning, and text-prompted editing. Through ablating the 3D functionality of our model, we demonstrate that the inclusion of text, 2D, and 3D representations significantly improves performance on the downstream tasks.