Bioinfo-Bench: A Simple Benchmark Framework for LLM Bioinformatics Skills Evaluation
Bioinfo-Bench: A Simple Benchmark Framework for LLM Bioinformatics Skills Evaluation
Chen, Q.; Deng, C.
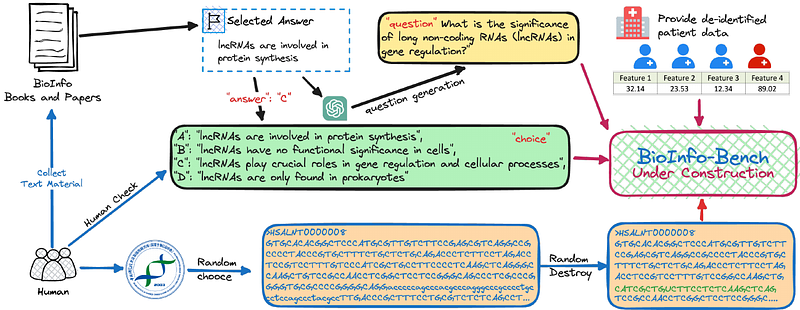
AbstractLarge Language Models (LLMs) have garnered significant recognition in the life sciences for their capacity to comprehend and utilize knowledge. The contemporary expectation in diverse industries extends beyond employing LLMs merely as chatbots; instead, there is a growing emphasis on harnessing their potential as adept analysts proficient in dissecting intricate issues within these sectors. The realm of bioinformatics is no exception to this trend. In this paper, we introduce Bioinfo-Bench, a novel yet straightforward benchmark framework suite crafted to assess the academic knowledge and data mining capabilities of foundational models in bioinformatics. Bioinfo-Bench systematically gathered data from three distinct perspectives: knowledge acquisition, knowledge analysis, and knowledge application, facilitating a comprehensive examination of LLMs. Our evaluation encompassed prominent models ChatGPT, Llama, and Galactica. The findings revealed that these LLMs excel in knowledge acquisition, drawing heavily upon their training data for retention. However, their proficiency in addressing practical professional queries and conducting nuanced knowledge inference remains constrained. Given these insights, we are poised to delve deeper into this domain, engaging in further extensive research and discourse. It is pertinent to note that project Bioinfo-Bench is currently in progress, and all associated materials will be made publicly accessible.