Leveraging synthetic data produced from museum specimens to train adaptable species classification models
Leveraging synthetic data produced from museum specimens to train adaptable species classification models
Blair, J. D.; Khidas, K.; Marshall, K. E.
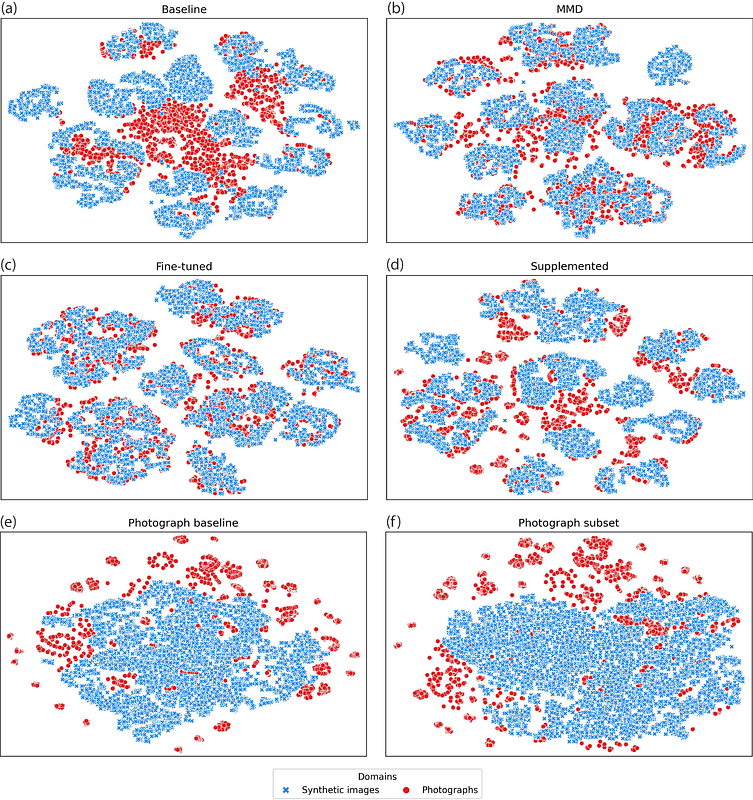
AbstractComputer vision has increasingly shown potential to improve data processing efficiency in ecological research. However, training computer vision models requires large amounts of high-quality, annotated training data. This poses a significant challenge for researchers looking to create bespoke computer vision models, as substantial human resources and biological replicates are often needed to adequately train these models. Synthetic images have been proposed as a potential solution for generating large training datasets, but models trained with synthetic images often have poor generalization to real photographs. Here we present a modular pipeline for training generalizable classification models using synthetic images. Our pipeline includes 3D asset creation with the use of 3D scanners, synthetic image generation with open-source computer graphic software, and domain adaptive classification model training. We demonstrate our pipeline by applying it to skulls of 16 mammal species in the order Carnivora. We explore several domain adaptation techniques, including maximum mean discrepancy (MMD) loss, fine-tuning, and data supplementation. Using our pipeline, we were able to improve classification accuracy on real photographs from 55.4% to a maximum of 95.1%. We also conducted qualitative analysis with t-distributed stochastic neighbor embedding (t-SNE) and gradient-weighted class activation mapping (Grad-CAM) to compare different domain adaptation techniques. Our results demonstrate the feasibility of using synthetic images for ecological computer vision and highlight the potential of museum specimens and 3D assets for scalable, generalizable model training.