A Benchmarking Study of Feature Screening Approaches Across Omics Classification Settings
A Benchmarking Study of Feature Screening Approaches Across Omics Classification Settings
VonKaenel, E.; Bramer, L.; Flores, J.; Metz, T.; Nakayasu, E. S.; Webb-Robertson, B.-J.
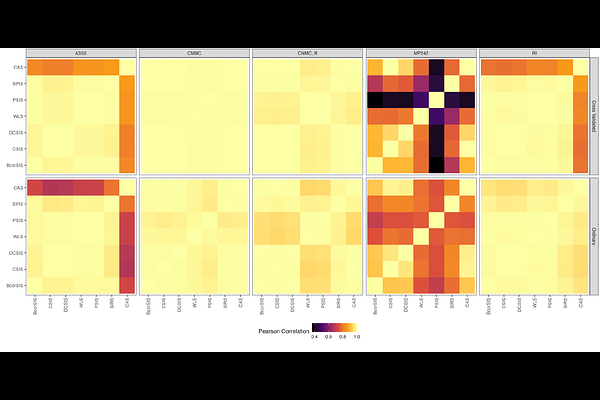
AbstractIn recent years, high dimensional omics analyses have become more commonplace for investigating complex biological systems. Typically, these studies attempt to identify key biomolecules associated with a particular biological process. Often, machine learning (ML) is used to identify these biomolecules, typically by learning which biomolecules are highly predictive of a treatment, biological outcome, or phenotype. A major challenge of applying ML to high throughput omics is overcoming noise when sample size is limited and unbalanced with respect to tens of thousands of biomolecules measured. Thus, feature selection (the process of reducing the number of predictors) is both a critical and common step in the ML analysis pipeline. While much attention has been given to embedding and wrapping techniques for feature selection in the omics space, filter-based methods for model-free feature selection have appealing theoretical properties. This manuscript evaluates sure screening, a class of filter-based feature selection methods which provide analytical guarantees for true feature set retention. Here, we cover existing feature screening methods based on the sure screening principal, available software, methods to improve feature screening, and contextualize feature screening in the larger discussion of feature selection for omics data analysis. Additionally, a suite of model-free sure screening approaches is applied and compared for several omics biomedical applications in a ML classification context. We identified BcorSIS as the most effective and computationally efficient screening method across various omics datasets, consistently outperforming others like CSIS and DCSIS in runtime.