BayesCurveFit: Enhancing Curve Fitting in Drug Discovery with Bayesian Inference
BayesCurveFit: Enhancing Curve Fitting in Drug Discovery with Bayesian Inference
Du, N.; Chen, Y.; Qian, Y.
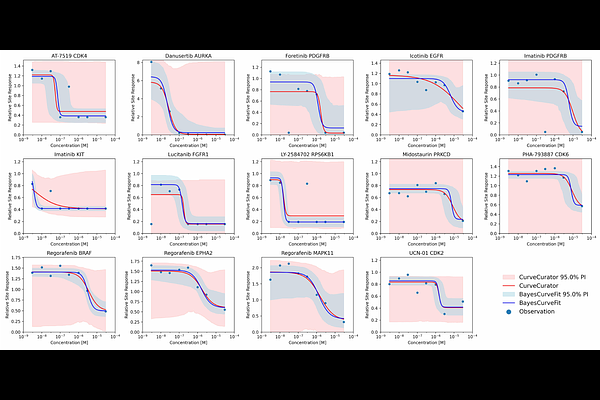
AbstractCurve fitting is a key statistical method in the pharmaceutical industry for modeling the relationship between drug effects and dose levels. Traditional regression-based curve fitting is computationally efficient but sensitive to technical errors, particularly with small sample sizes. In practice, budget constraints often limit the number of dose levels that can be tested. We hypothesize that Bayesian inference offers a more robust alternative in resource-constrained settings. We developed BayesCurveFit, a pipeline that consists of three Bayesian techniques for dose-response curve fitting: Simulated Annealing (SA) for initial parameter estimation, Markov Chain Monte Carlo (MCMC) for posterior sampling, and Bayesian Model Averaging (BMA) to integrate predictions from multiple models. Our simulations demonstrated that BayesCurveFit outperforms regression-based methods on under-sampled data, with performance converging as sample size increases. Benchmarking experiments showed BayesCurveFit achieves higher accuracy than Ordinary Least Squares (OLS) and soft L1 regression when working with 10 or fewer observations. A real-world case study using the Kinobeads dataset further validated BayesCurveFit, revealing multiple novel drug-gene interactions overlooked by the popular OLS-based CurveCurator method. These interactions were confirmed in ChEMBL, a manually curated drug discovery database. These findings underscore BayesCurveFit\'s advantages in data-limited scenarios. BayesCurveFit is available as an open-source Python package, with the reprocessed Kinobeads dataset accessible via a web-based interface for public testing and validation.