Do chemical language models provide a better compound representation?
Do chemical language models provide a better compound representation?
Torrisi, M.; Asadollahi, S.; de la Vega de Leon, A.; Wang, K.; Copeland, W.
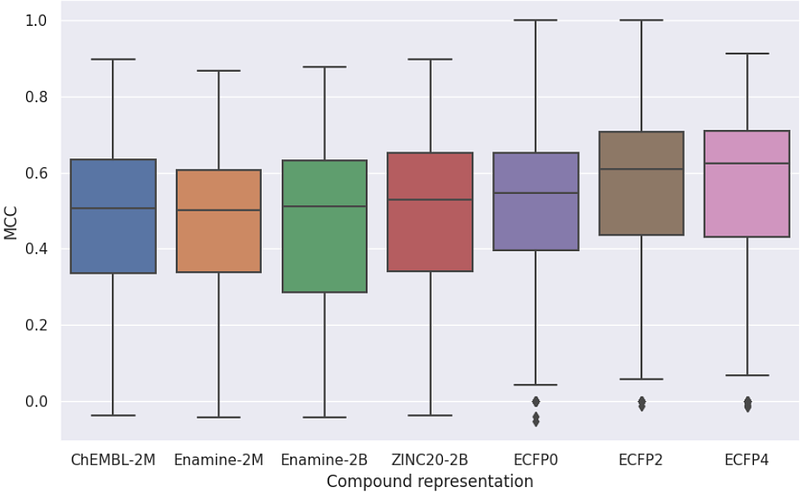
AbstractIn recent years, several chemical language models have been developed, inspired by the success of protein language models and advancements in natural language processing. In this study, we explore whether pre-training a chemical language model on billion-scale compound datasets, such as Enamine and ZINC20, can lead to improved compound representation in the drug space. We compare the learned representations of these models with the de facto standard compound representation, and evaluate their potential application in drug discovery and development by benchmarking them on biophysics, physiology, and physical chemistry datasets. Our findings suggest that the conventional masked language modeling approach on these extensive pre-training datasets is insufficient in enhancing compound representations. This highlights the need for additional physicochemical inductive bias in the modeling beyond scaling the dataset size.