Preprint-to-PPT
Casts
Team
Blog
News
Articles
More
Welcome
Investor Information
Terms
Contact ScienceCast
Sign Up
Sign Up
Log In
MBTFNet: Multi-Band Temporal-Frequency Neural ...
Sound
Weiming Xu
186 views
An Integrated Algorithm for Robust and Imperce...
Sound
Armin Ettenhofer
256 views
Deep Generative Models of Music Expectation
Sound
Ninon Lizé Masclef
160 views
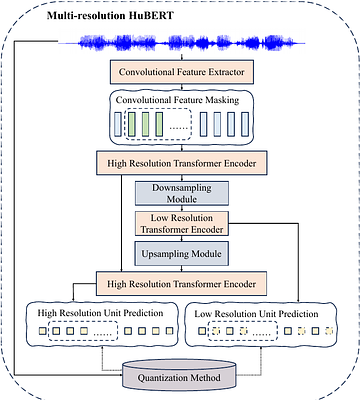
Multi-resolution HuBERT: Multi-resolution Spee...
Sound
Jiatong Shi
238 views
BA-MoE: Boundary-Aware Mixture-of-Experts Adap...
Sound
Peikun Chen
146 views
Mel-Band RoFormer for Music Source Separation
Sound
Ju-Chiang Wang
275 views
Improving Audio Captioning Models with Fine-gr...
Sound
Shih-Lun Wu
134 views
RTFS-Net: Recurrent time-frequency modelling f...
Sound
Samuel Pegg
107 views
DiffAR: Denoising Diffusion Autoregressive Mod...
Sound
Roi Benita
119 views
ReFlow-TTS: A Rectified Flow Model for High-fi...
Sound
Wenhao Guan
185 views
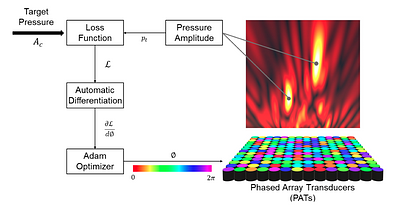
Acoustic Hologram Optimisation Using Automatic...
Sound
tfushimi
408 views