Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction
Multi-resolution HuBERT: Multi-resolution Speech Self-Supervised Learning with Masked Unit Prediction
Jiatong Shi, Hirofumi Inaguma, Xutai Ma, Ilia Kulikov, Anna Sun
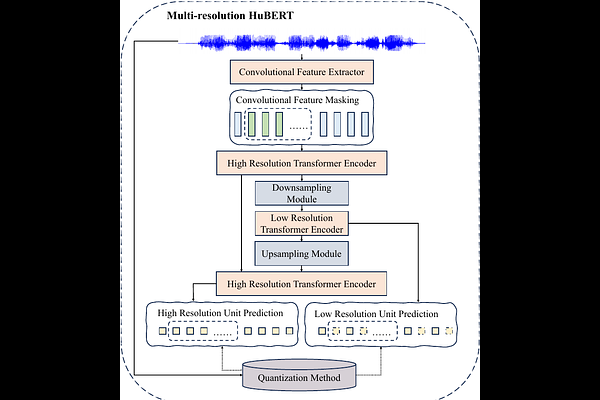
AbstractExisting Self-Supervised Learning (SSL) models for speech typically process speech signals at a fixed resolution of 20 milliseconds. This approach overlooks the varying informational content present at different resolutions in speech signals. In contrast, this paper aims to incorporate multi-resolution information into speech self-supervised representation learning. We introduce a SSL model that leverages a hierarchical Transformer architecture, complemented by HuBERT-style masked prediction objectives, to process speech at multiple resolutions. Experimental results indicate that the proposed model not only achieves more efficient inference but also exhibits superior or comparable performance to the original HuBERT model over various tasks. Specifically, significant performance improvements over the original HuBERT have been observed in fine-tuning experiments on the LibriSpeech speech recognition benchmark as well as in evaluations using the Speech Universal PERformance Benchmark (SUPERB) and Multilingual SUPERB (ML-SUPERB).