By: Dmitrii Zendrikov, Alessio Franci, Giacomo Indiveri
Neural systems use the same underlying computational substrate to carry out analog filtering and signal processing operations, as well as discrete symbol manipulation and digital computation. Inspired by the computational principles of canonical cortical microcircuits, we propose a framework for using recurrent spiking neural networks to seamlessly and robustly switch between analog signal processing and categorical and discrete computation... more
Neural systems use the same underlying computational substrate to carry out analog filtering and signal processing operations, as well as discrete symbol manipulation and digital computation. Inspired by the computational principles of canonical cortical microcircuits, we propose a framework for using recurrent spiking neural networks to seamlessly and robustly switch between analog signal processing and categorical and discrete computation. We provide theoretical analysis and practical neural network design tools to formally determine the conditions for inducing this switch. We demonstrate the robustness of this framework experimentally with hardware soft Winner-Take-All and mixed-feedback recurrent spiking neural networks, implemented by appropriately configuring the analog neuron and synapse circuits of a mixed-signal neuromorphic processor chip. less
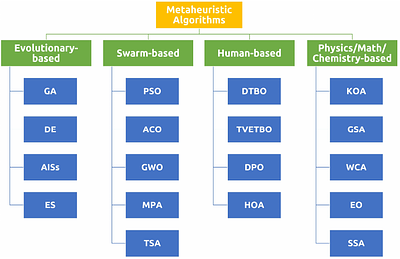
By: Dler O. Hasan, Hardi M. Mohammed, Zrar Khalid Abdul
The FOX optimizer, inspired by red fox hunting behavior, is a powerful algorithm for solving real-world and engineering problems. However, despite balancing exploration and exploitation, it can prematurely converge to local optima, as agent positions are updated solely based on the current best-known position, causing all agents to converge on one location. This study proposes the modified FOX optimizer (mFOX) to enhance exploration and bal... more
The FOX optimizer, inspired by red fox hunting behavior, is a powerful algorithm for solving real-world and engineering problems. However, despite balancing exploration and exploitation, it can prematurely converge to local optima, as agent positions are updated solely based on the current best-known position, causing all agents to converge on one location. This study proposes the modified FOX optimizer (mFOX) to enhance exploration and balance exploration and exploitation in three steps. First, the Oppositional-Based Learning (OBL) strategy is used to improve the initial population. Second, control parameters are refined to achieve a better balance between exploration and exploitation. Third, a new update equation is introduced, allowing agents to adjust their positions relative to one another rather than relying solely on the best-known position. This approach improves exploration efficiency without adding complexity. The mFOX algorithm's performance is evaluated against 12 well-known algorithms on 23 classical benchmark functions, 10 CEC2019 functions, and 12 CEC2022 functions. It outperforms competitors in 74% of the classical benchmarks, 60% of the CEC2019 benchmarks, and 58% of the CEC2022 benchmarks. Additionally, mFOX effectively addresses four engineering problems. These results demonstrate mFOX's strong competitiveness in solving complex optimization tasks, including unimodal, constrained, and high-dimensional problems. less

By: Boxun Xu, Junyoung Hwang, Pruek Vanna-iampikul, Yuxuan Yin, Sung Kyu Lim, Peng Li
Spiking Neural Networks(SNNs) provide a brain-inspired and event-driven mechanism that is believed to be critical to unlock energy-efficient deep learning. The mixture-of-experts approach mirrors the parallel distributed processing of nervous systems, introducing conditional computation policies and expanding model capacity without scaling up the number of computational operations. Additionally, spiking mixture-of-experts self-attention mec... more
Spiking Neural Networks(SNNs) provide a brain-inspired and event-driven mechanism that is believed to be critical to unlock energy-efficient deep learning. The mixture-of-experts approach mirrors the parallel distributed processing of nervous systems, introducing conditional computation policies and expanding model capacity without scaling up the number of computational operations. Additionally, spiking mixture-of-experts self-attention mechanisms enhance representation capacity, effectively capturing diverse patterns of entities and dependencies between visual or linguistic tokens. However, there is currently a lack of hardware support for highly parallel distributed processing needed by spiking transformers, which embody a brain-inspired computation. This paper introduces the first 3D hardware architecture and design methodology for Mixture-of-Experts and Multi-Head Attention spiking transformers. By leveraging 3D integration with memory-on-logic and logic-on-logic stacking, we explore such brain-inspired accelerators with spatially stackable circuitry, demonstrating significant optimization of energy efficiency and latency compared to conventional 2D CMOS integration. less
4 SciCasts by .
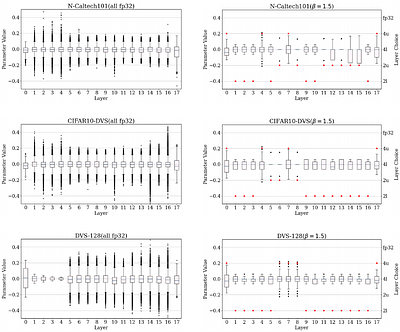
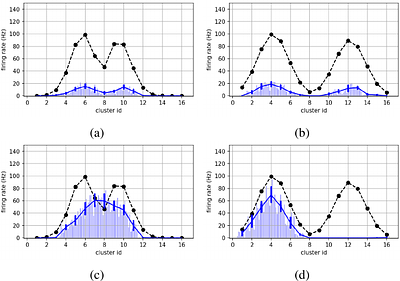
By: Boxun Xu, Yufei Song, Peng Li
Spiking Neural Networks (SNNs) are amenable to deployment on edge devices and neuromorphic hardware due to their lower dissipation. Recently, SNN-based transformers have garnered significant interest, incorporating attention mechanisms akin to their counterparts in Artificial Neural Networks (ANNs) while demonstrating excellent performance. However, deploying large spiking transformer models on resource-constrained edge devices such as mobi... more
Spiking Neural Networks (SNNs) are amenable to deployment on edge devices and neuromorphic hardware due to their lower dissipation. Recently, SNN-based transformers have garnered significant interest, incorporating attention mechanisms akin to their counterparts in Artificial Neural Networks (ANNs) while demonstrating excellent performance. However, deploying large spiking transformer models on resource-constrained edge devices such as mobile phones, still poses significant challenges resulted from the high computational demands of large uncompressed high-precision models. In this work, we introduce a novel heterogeneous quantization method for compressing spiking transformers through layer-wise quantization. Our approach optimizes the quantization of each layer using one of two distinct quantization schemes, i.e., uniform or power-of-two quantification, with mixed bit resolutions. Our heterogeneous quantization demonstrates the feasibility of maintaining high performance for spiking transformers while utilizing an average effective resolution of 3.14-3.67 bits with less than a 1% accuracy drop on DVS Gesture and CIFAR10-DVS datasets. It attains a model compression rate of 8.71x-10.19x for standard floating-point spiking transformers. Moreover, the proposed approach achieves a significant energy reduction of 5.69x, 8.72x, and 10.2x while maintaining high accuracy levels of 85.3%, 97.57%, and 80.4% on N-Caltech101, DVS-Gesture, and CIFAR10-DVS datasets, respectively. less
By: Francesco Innocenti, Paul Kinghorn, Will Yun-Farmbrough, Miguel De Llanza Varona, Ryan Singh, Christopher L. Buckley
We introduce JPC, a JAX library for training neural networks with Predictive Coding. JPC provides a simple, fast and flexible interface to train a variety of PC networks (PCNs) including discriminative, generative and hybrid models. Unlike existing libraries, JPC leverages ordinary differential equation solvers to integrate the gradient flow inference dynamics of PCNs. We find that a second-order solver achieves significantly faster runtime... more
We introduce JPC, a JAX library for training neural networks with Predictive Coding. JPC provides a simple, fast and flexible interface to train a variety of PC networks (PCNs) including discriminative, generative and hybrid models. Unlike existing libraries, JPC leverages ordinary differential equation solvers to integrate the gradient flow inference dynamics of PCNs. We find that a second-order solver achieves significantly faster runtimes compared to standard Euler integration, with comparable performance on a range of tasks and network depths. JPC also provides some theoretical tools that can be used to study PCNs. We hope that JPC will facilitate future research of PC. The code is available at https://github.com/thebuckleylab/jpc. less
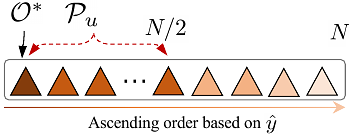
By: Hao Hao, Xiaoqun Zhang, Aimin Zhou
Expensive optimization problems (EOPs) are prevalent in real-world applications, where the evaluation of a single solution requires a significant amount of resources. In our study of surrogate-assisted evolutionary algorithms (SAEAs) in EOPs, we discovered an intriguing phenomenon. Because only a limited number of solutions are evaluated in each iteration, relying solely on these evaluated solutions for evolution can lead to reduced dispari... more
Expensive optimization problems (EOPs) are prevalent in real-world applications, where the evaluation of a single solution requires a significant amount of resources. In our study of surrogate-assisted evolutionary algorithms (SAEAs) in EOPs, we discovered an intriguing phenomenon. Because only a limited number of solutions are evaluated in each iteration, relying solely on these evaluated solutions for evolution can lead to reduced disparity in successive populations. This, in turn, hampers the reproduction operators' ability to generate superior solutions, thereby reducing the algorithm's convergence speed. To address this issue, we propose a strategic approach that incorporates high-quality, un-evaluated solutions predicted by surrogate models during the selection phase. This approach aims to improve the distribution of evaluated solutions, thereby generating a superior next generation of solutions. This work details specific implementations of this concept across various reproduction operators and validates its effectiveness using multiple surrogate models. Experimental results demonstrate that the proposed strategy significantly enhances the performance of surrogate-assisted evolutionary algorithms. Compared to mainstream SAEAs and Bayesian optimization algorithms, our approach incorporating the un-evaluated solution strategy shows a marked improvement. less
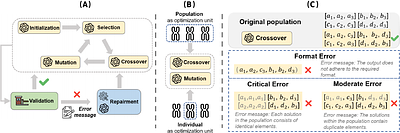
By: Jie Zhao, Tao Wen, Kang Hao Cheong
Evolutionary computation excels in complex optimization but demands deep domain knowledge, restricting its accessibility. Large Language Models (LLMs) offer a game-changing solution with their extensive knowledge and could democratize the optimization paradigm. Although LLMs possess significant capabilities, they may not be universally effective, particularly since evolutionary optimization encompasses multiple stages. It is therefore imper... more
Evolutionary computation excels in complex optimization but demands deep domain knowledge, restricting its accessibility. Large Language Models (LLMs) offer a game-changing solution with their extensive knowledge and could democratize the optimization paradigm. Although LLMs possess significant capabilities, they may not be universally effective, particularly since evolutionary optimization encompasses multiple stages. It is therefore imperative to evaluate the suitability of LLMs as evolutionary optimizer (EVO). Thus, we establish a series of rigid standards to thoroughly examine the fidelity of LLM-based EVO output in different stages of evolutionary optimization and then introduce a robust error-correction mechanism to mitigate the output uncertainty. Furthermore, we explore a cost-efficient method that directly operates on entire populations with excellent effectiveness in contrast to individual-level optimization. Through extensive experiments, we rigorously validate the performance of LLMs as operators targeted for combinatorial problems. Our findings provide critical insights and valuable observations, advancing the understanding and application of LLM-based optimization. less