By: Michelle Seng Ah Lee, Kirtan Padh, David Watson, Niki Kilbertus, Jatinder Singh
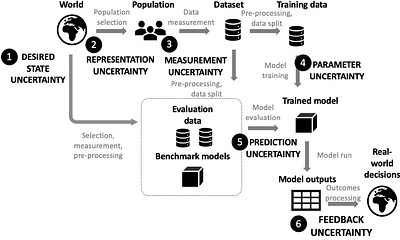
Fair machine learning (ML) methods help identify and mitigate the risk that algorithms encode or automate social injustices. Algorithmic approaches alone cannot resolve structural inequalities, but they can support socio-technical decision systems by surfacing discriminatory biases, clarifying trade-offs, and enabling governance. Although fairness is well studied in supervised learning, many real ML applications are online and sequential, wit... more
Fair machine learning (ML) methods help identify and mitigate the risk that algorithms encode or automate social injustices. Algorithmic approaches alone cannot resolve structural inequalities, but they can support socio-technical decision systems by surfacing discriminatory biases, clarifying trade-offs, and enabling governance. Although fairness is well studied in supervised learning, many real ML applications are online and sequential, with prior decisions informing future ones. Each decision is taken under uncertainty due to unobserved counterfactuals and finite samples, with dire consequences for under-represented groups, systematically under-observed due to historical exclusion and selective feedback. A bank cannot know whether a denied loan would have been repaid, and may have less data on marginalized populations. This paper introduces a taxonomy of uncertainty in sequential decision-making -- model, feedback, and prediction uncertainty -- providing shared vocabulary for assessing systems where uncertainty is unevenly distributed across groups. We formalize model and feedback uncertainty via counterfactual logic and reinforcement learning, and illustrate harms to decision makers (unrealized gains/losses) and subjects (compounding exclusion, reduced access) of policies that ignore the unobserved space. Algorithmic examples show it is possible to reduce outcome variance for disadvantaged groups while preserving institutional objectives (e.g. expected utility). Experiments on data simulated with varying bias show how unequal uncertainty and selective feedback produce disparities, and how uncertainty-aware exploration alters fairness metrics. The framework equips practitioners to diagnose, audit, and govern fairness risks. Where uncertainty drives unfairness rather than incidental noise, accounting for it is essential to fair and effective decision-making. less

By: Jian Cheng Wong, Isaac Yin Chung Lai, Pao-Hsiung Chiu, Chin Chun Ooi, Abhishek Gupta, Yew-Soon Ong
Physics-informed neural networks (PINNs) have garnered significant interest for their potential in solving partial differential equations (PDEs) that govern a wide range of physical phenomena. By incorporating physical laws into the learning process, PINN models have demonstrated the ability to learn physical outcomes reasonably well. However, current PINN approaches struggle to predict or solve new PDEs effectively when there is a lack of tr... more
Physics-informed neural networks (PINNs) have garnered significant interest for their potential in solving partial differential equations (PDEs) that govern a wide range of physical phenomena. By incorporating physical laws into the learning process, PINN models have demonstrated the ability to learn physical outcomes reasonably well. However, current PINN approaches struggle to predict or solve new PDEs effectively when there is a lack of training examples, indicating they do not generalize well to unseen problem instances. In this paper, we present a transferable learning approach for PINNs premised on a fast Pseudoinverse PINN framework (Pi-PINN). Pi-PINN learns a transferable physics-informed representation in a shared embedding space and enables rapid solving of both known and unknown PDE instances via closed-form head adaptation using a least-squares-optimal pseudoinverse under PDE constraints. We further investigate the synergies between data-driven multi-task learning loss and physics-informed loss, providing insights into the design of more performant PINNs. We demonstrate the effectiveness of Pi-PINN on various PDE problems, including Poisson's equation, Helmholtz equation, and Burgers' equation, achieving fast and accurate physics-informed solutions without requiring any data for unseen instances. Pi-PINN can produce predictions 100-1000 times faster than a typical PINN, while producing predictions with 10-100 times lower relative error than a typical data-driven model even with only two training samples. Overall, our findings highlight the potential of transferable representations with closed-form head adaptation to enhance the efficiency and generalization of PINNs across PDE families and scientific and engineering applications. less
By: Bingcong Li, Yilang Zhang, Georgios B. Giannakis
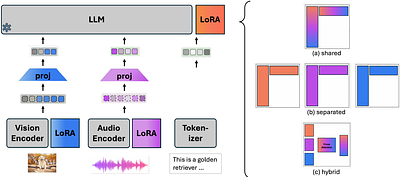
Low-rank adaptation (LoRA) has emerged as the de facto standard for parameter-efficient fine-tuning (PEFT) of foundation models, enabling the adaptation of billion-parameter networks with minimal computational and memory overhead. Despite its empirical success and rapid proliferation of variants, it remains elusive which architectural choices, optimization techniques, and deployment constraints should guide practical method selection. This ov... more
Low-rank adaptation (LoRA) has emerged as the de facto standard for parameter-efficient fine-tuning (PEFT) of foundation models, enabling the adaptation of billion-parameter networks with minimal computational and memory overhead. Despite its empirical success and rapid proliferation of variants, it remains elusive which architectural choices, optimization techniques, and deployment constraints should guide practical method selection. This overview revisits LoRA through the lens of signal processing (SP), bridging modern adapter designs with classical low-rank modeling tools and inverse problems, as well as highlighting how SP principles can inform principled advances of fine-tuning approaches. Rather than providing a comprehensive enumeration and empirical comparisons of LoRA variants, emphasis is placed on the technical mechanisms underpinning these approaches to justify their effectiveness. These advances are categorized into three complementary axes: architectural design, efficient optimization, and pertinent applications. The first axis builds on singular value decomposition (SVD)-based factorization, rank-augmentation constructions, and cross-layer tensorization, while the second axis deals with initialization, alternating solvers, gauge-invariant optimization, and parameterization-aware methods. Beyond fine-tuning, emerging applications of LoRA are accounted across the entire lifecycle of large models, ranging from pre- and post-training to serving/deployment. Finally, open research directions are outlined at the confluence of SP and deep learning to catalyze a bidirectional frontier: classical SP tools provide a principled vocabulary for designing principled PEFT methods, while the unique challenges facing modern deep learning, especially the overwhelming scale and prohibitive overhead, also offer new research lines benefiting the SP community in return. less
By: Natalie Collina, Jiuyao Lu, Georgy Noarov, Aaron Roth
We study the minimax sample complexity of multicalibration in the batch setting. A learner observes $n$ i.i.d. samples from an unknown distribution and must output a (possibly randomized) predictor whose population multicalibration error, measured by Expected Calibration Error (ECE), is at most $\varepsilon$ with respect to a given family of groups. For every fixed $κ> 0$, in the regime $|G|\le \varepsilon^{-κ}$, we prove that $\widetildeΘ(\v... more
We study the minimax sample complexity of multicalibration in the batch setting. A learner observes $n$ i.i.d. samples from an unknown distribution and must output a (possibly randomized) predictor whose population multicalibration error, measured by Expected Calibration Error (ECE), is at most $\varepsilon$ with respect to a given family of groups. For every fixed $κ> 0$, in the regime $|G|\le \varepsilon^{-κ}$, we prove that $\widetildeΘ(\varepsilon^{-3})$ samples are necessary and sufficient, up to polylogarithmic factors. The lower bound holds even for randomized predictors, and the upper bound is realized by a randomized predictor obtained via an online-to-batch reduction. This separates the sample complexity of multicalibration from that of marginal calibration, which scales as $\widetildeΘ(\varepsilon^{-2})$, and shows that mean-ECE multicalibration is as difficult in the batch setting as it is in the online setting, in contrast to marginal calibration which is strictly more difficult in the online setting. In contrast we observe that for $κ= 0$, the sample complexity of multicalibration remains $\widetildeΘ(\varepsilon^{-2})$ exhibiting a sharp threshold phenomenon. More generally, we establish matching upper and lower bounds, up to polylogarithmic factors, for a weighted $L_p$ multicalibration metric for all $1 \le p \le 2$, with optimal exponent $3/p$. We also extend the lower-bound template to a regular class of elicitable properties, and combine it with the online upper bounds of Hu et al. (2025) to obtain matching bounds for calibrating properties including expectiles and bounded-density quantiles. less
By: Nicolae Filat, Ahmed Hussain, Konstantinos Kalogiannis, Elena Burceanu
Streaming Continual Learning (CL) typically converts a continuous stream into a sequence of discrete tasks through temporal partitioning. We argue that this temporal taskification step is not a neutral preprocessing choice, but a structural component of evaluation: different valid splits of the same stream can induce different CL regimes and therefore different benchmark conclusions. To study this effect, we introduce a taskification-level fr... more
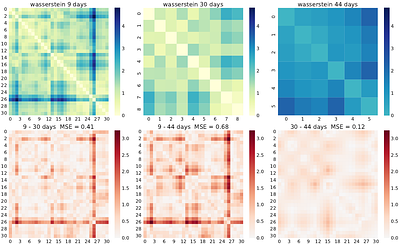
Streaming Continual Learning (CL) typically converts a continuous stream into a sequence of discrete tasks through temporal partitioning. We argue that this temporal taskification step is not a neutral preprocessing choice, but a structural component of evaluation: different valid splits of the same stream can induce different CL regimes and therefore different benchmark conclusions. To study this effect, we introduce a taskification-level framework based on plasticity and stability profiles, a profile distance between taskifications, and Boundary-Profile Sensitivity (BPS), which diagnoses how strongly small boundary perturbations alter the induced regime before any CL model is trained. We evaluate continual finetuning, Experience Replay, Elastic Weight Consolidation, and Learning without Forgetting on network traffic forecasting with CESNET-Timeseries24, keeping the stream, model, and training budget fixed while varying only the temporal taskification. Across 9-, 30-, and 44-day splits, we observe substantial changes in forecasting error, forgetting, and backward transfer, showing that taskification alone can materially affect CL evaluation. We further find that shorter taskifications induce noisier distribution-level patterns, larger structural distances, and higher BPS, indicating greater sensitivity to boundary perturbations. These results show that benchmark conclusions in streaming CL depend not only on the learner and the data stream, but also on how that stream is taskified, motivating temporal taskification as a first-class evaluation variable. less
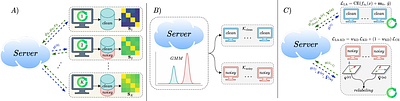
FedSIR: Spectral Client Identification and Relabeling for Federated Learning with Noisy Labels
0upvotes
By: Sina Gholami, Abdulmoneam Ali, Tania Haghighi, Ahmed Arafa, Minhaj Nur Alam
Federated learning (FL) enables collaborative model training without sharing raw data; however, the presence of noisy labels across distributed clients can severely degrade the learning performance. In this paper, we propose FedSIR, a multi-stage framework for robust FL under noisy labels. Different from existing approaches that mainly rely on designing noise-tolerant loss functions or exploiting loss dynamics during training, our method leve... more
Federated learning (FL) enables collaborative model training without sharing raw data; however, the presence of noisy labels across distributed clients can severely degrade the learning performance. In this paper, we propose FedSIR, a multi-stage framework for robust FL under noisy labels. Different from existing approaches that mainly rely on designing noise-tolerant loss functions or exploiting loss dynamics during training, our method leverages the spectral structure of client feature representations to identify and mitigate label noise. Our framework consists of three key components. First, we identify clean and noisy clients by analyzing the spectral consistency of class-wise feature subspaces with minimal communication overhead. Second, clean clients provide spectral references that enable noisy clients to relabel potentially corrupted samples using both dominant class directions and residual subspaces. Third, we employ a noise-aware training strategy that integrates logit-adjusted loss, knowledge distillation, and distance-aware aggregation to further stabilize federated optimization. Extensive experiments on standard FL benchmarks demonstrate that FedSIR consistently outperforms state-of-the-art methods for FL with noisy labels. The code is available at https://github.com/sinagh72/FedSIR. less

Relative Entropy Estimation in Function Space: Theory and Applications to Trajectory Inference
0upvotes
By: Chao Wang, Luca Nepote, Giulio Franzese, Pietro Michiardi
Trajectory Inference (TI) seeks to recover latent dynamical processes from snapshot data, where only independent samples from time-indexed marginals are observed. In applications such as single-cell genomics, destructive measurements make path-space laws non-identifiable from finitely many marginals, leaving held-out marginal prediction as the dominant but limited evaluation protocol. We introduce a general framework for estimating the Kullba... more
Trajectory Inference (TI) seeks to recover latent dynamical processes from snapshot data, where only independent samples from time-indexed marginals are observed. In applications such as single-cell genomics, destructive measurements make path-space laws non-identifiable from finitely many marginals, leaving held-out marginal prediction as the dominant but limited evaluation protocol. We introduce a general framework for estimating the Kullback-Leibler divergence (KL) divergence between probability measures on function space, yielding a tractable, data-driven estimator that is scalable to realistic snapshot datasets. We validate the accuracy of our estimator on a benchmark suite, where the estimated functional KL closely matches the analytic KL. Applying this framework to synthetic and real scRNA-seq datasets, we show that current evaluation metrics often give inconsistent assessments, whereas path-space KL enables a coherent comparison of trajectory inference methods and exposes discrepancies in inferred dynamics, especially in regions with sparse or missing data. These results support functional KL as a principled criterion for evaluating trajectory inference under partial observability. less
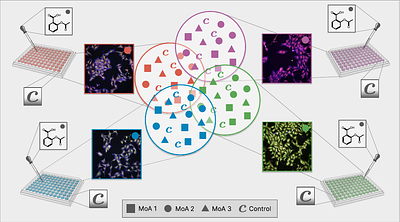
By: Ana Sanchez-Fernandez, Thomas Pinetz, Werner Zellinger, Günter Klambauer
The central problem in biomedical imaging are batch effects: systematic technical variations unrelated to the biological signal of interest. These batch effects critically undermine experimental reproducibility and are the primary cause of failure of deep learning systems on new experimental batches, preventing their practical use in the real world. Despite years of research, no method has succeeded in closing this performance gap for deep le... more
The central problem in biomedical imaging are batch effects: systematic technical variations unrelated to the biological signal of interest. These batch effects critically undermine experimental reproducibility and are the primary cause of failure of deep learning systems on new experimental batches, preventing their practical use in the real world. Despite years of research, no method has succeeded in closing this performance gap for deep learning models. We propose Control-Stabilized Adaptive Risk Minimization via Batch Normalization (CS-ARM-BN), a meta-learning adaptation method that exploits negative control samples. Such unperturbed reference images are present in every experimental batch by design and serve as stable context for adaptation. We validate our novel method on Mechanism-of-Action (MoA) classification, a crucial task for drug discovery, on the large-scale JUMP-CP dataset. The accuracy of standard ResNets drops from 0.939 $\pm$ 0.005, on the training domain, to 0.862 $\pm$ 0.060 on data from new experimental batches. Foundation models, even after Typical Variation Normalization, fail to close this gap. We are the first to show that meta-learning approaches close the domain gap by achieving 0.935 $\pm$ 0.018. If the new experimental batches exhibit strong domain shifts, such as being generated in a different lab, meta-learning approaches can be stabilized with control samples, which are always available in biomedical experiments. Our work shows that batch effects in bioimaging data can be effectively neutralized through principled in-context adaptation, which also makes them practically usable and efficient. less

By: Shelly Golan, Michael Finkelson, Ariel Bereslavsky, Yotam Nitzan, Or Patashnik
Reinforcement Learning (RL) post-training has become the standard for aligning generative models with human preferences, yet most methods rely on a single scalar reward. When multiple criteria matter, the prevailing practice of ``early scalarization'' collapses rewards into a fixed weighted sum. This commits the model to a single trade-off point at training time, providing no inference-time control over inherently conflicting goals -- such as... more
Reinforcement Learning (RL) post-training has become the standard for aligning generative models with human preferences, yet most methods rely on a single scalar reward. When multiple criteria matter, the prevailing practice of ``early scalarization'' collapses rewards into a fixed weighted sum. This commits the model to a single trade-off point at training time, providing no inference-time control over inherently conflicting goals -- such as prompt adherence versus source fidelity in image editing. We introduce ParetoSlider, a multi-objective RL (MORL) framework that trains a single diffusion model to approximate the entire Pareto front. By training the model with continuously varying preference weights as a conditioning signal, we enable users to navigate optimal trade-offs at inference time without retraining or maintaining multiple checkpoints. We evaluate ParetoSlider across three state-of-the-art flow-matching backbones: SD3.5, FluxKontext, and LTX-2. Our single preference-conditioned model matches or exceeds the performance of baselines trained separately for fixed reward trade-offs, while uniquely providing fine-grained control over competing generative goals. less
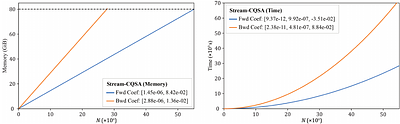
Stream-CQSA: Avoiding Out-of-Memory in Attention Computation via Flexible Workload Scheduling
0upvotes
By: Yiming Bian, Joshua M. Akey
The scalability of long-context large language models is fundamentally limited by the quadratic memory cost of exact self-attention, which often leads to out-of-memory (OOM) failures on modern hardware. Existing methods improve memory efficiency to near-linear complexity, while assuming that the full query, key, and value tensors fit in device memory. In this work, we remove this assumption by introducing CQS Divide, an operation derived from... more
The scalability of long-context large language models is fundamentally limited by the quadratic memory cost of exact self-attention, which often leads to out-of-memory (OOM) failures on modern hardware. Existing methods improve memory efficiency to near-linear complexity, while assuming that the full query, key, and value tensors fit in device memory. In this work, we remove this assumption by introducing CQS Divide, an operation derived from cyclic quorum sets (CQS) theory that decomposes attention into a set of independent subsequence computations whose recomposition yields exactly the same result as full-sequence attention. Exploiting this decomposition, we introduce Stream-CQSA, a memory-adaptive scheduling framework that partitions attention into subproblems that fit within arbitrary memory budgets. This recasts attention from a logically monolithic operation into a collection of schedulable tasks, enabling flexible execution across devices without inter-device communication. Experiments demonstrate predictable memory scaling and show that exact attention over billion-token sequences can be executed on a single GPU via streaming, without changing the underlying mathematical definition of attention or introducing approximation error. less