By: Daniel Kuznetsov, Ziqi Wang
Federated learning is an emerging distributed paradigm that addresses the challenges posed by heterogeneous, privacy-sensitive data. It enables multiple clients to train a model collaboratively by aggregating their local updates at a server. However, conventional aggregation schemes typically use fixed weights that fail to reflect unequal and time-varying client contributions, leading to biased and unstable learning. To improve fairness and s... more
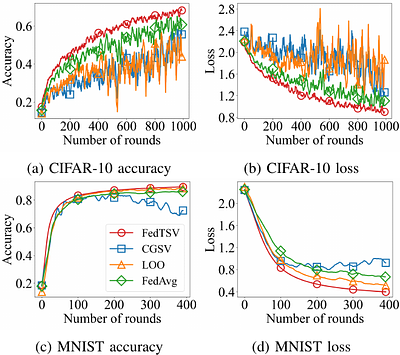
Federated learning is an emerging distributed paradigm that addresses the challenges posed by heterogeneous, privacy-sensitive data. It enables multiple clients to train a model collaboratively by aggregating their local updates at a server. However, conventional aggregation schemes typically use fixed weights that fail to reflect unequal and time-varying client contributions, leading to biased and unstable learning. To improve fairness and stability, we propose the Trajectory Shapley Value (TSV), a contribution metric that evaluates how each client influences the optimization trajectory of the global model using a validation-based, temporally consistent utility. Building on TSV, we design FedTSV, an adaptive aggregation method that converts per-round evaluations into dynamic client weights, allowing the server to respond to heterogeneous and adversarial participation in real time. Experiments on benchmark datasets show that FedTSV accelerates convergence, improves robustness, and yields more equitable contribution assessments, thereby providing a principled foundation for fairness-aware federated optimization. less
By: Fanny Lehmann, Firat Ozdemir, Yun Cheng, Torsten Hoefler, Sebastian Schemm, Benedikt Soja, Siddhartha Mishra
While AI weather models excel at short-to-medium range forecasts (up to 15 days), they frequently suffer from ill-defined "instabilities" when rolled out over longer horizons. This work addresses the lack of a formal taxonomy by categorizing these failures into three distinct regimes: blow-up, drift, and loss of seasonality, through year-long rollouts of nine state-of-the-art AI weather models. Our analysis reveals that stability hinges on th... more
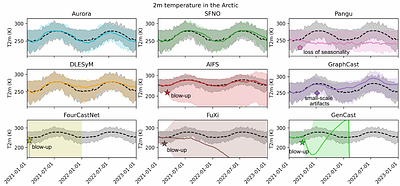
While AI weather models excel at short-to-medium range forecasts (up to 15 days), they frequently suffer from ill-defined "instabilities" when rolled out over longer horizons. This work addresses the lack of a formal taxonomy by categorizing these failures into three distinct regimes: blow-up, drift, and loss of seasonality, through year-long rollouts of nine state-of-the-art AI weather models. Our analysis reveals that stability hinges on the treatment of small spatio-temporal scales: unstable models amplify high-frequency energy, while stable models act as denoisers when noise is added to their inputs. Far from reducing these models to mere stochastic parrots, our findings highlight that stable models generate unique weather trajectories, conditioned on the initial state. We verify our findings through ablation studies on architectural design choices, conducted using state-of-the-art Vision Transformer (ViT) AI weather model architectures. less
By: Eugène Berta, David Holzmüller, Francis Bach, Michael I. Jordan
Reliable probability estimates are critical in many machine learning applications, yet modern classifiers are often poorly calibrated. Post-hoc calibration provides a simple and widely used solution, but the large number of proposed methods, combined with small-scale and inconsistent evaluations, makes it difficult to determine which approaches are truly effective in practice. We introduce a large-scale, standardized benchmark for post-hoc ca... more
Reliable probability estimates are critical in many machine learning applications, yet modern classifiers are often poorly calibrated. Post-hoc calibration provides a simple and widely used solution, but the large number of proposed methods, combined with small-scale and inconsistent evaluations, makes it difficult to determine which approaches are truly effective in practice. We introduce a large-scale, standardized benchmark for post-hoc calibration, covering nearly 2000 experiments across tabular and computer vision tasks, including binary, multiclass, and large-scale classification settings. Our benchmark aggregates predictions from a diverse set of classical models, modern deep learning architectures, and foundation models, and provides unified, reproducible implementations of dozens of calibration methods within a common evaluation framework. We argue that Post-Hoc Improvement (PHI) in proper scoring rules offers a principled alternative to traditional calibration error estimators for comparing post-hoc methods, capturing both calibration quality and potential degradation to the model's predictive performance. Using this framework, we conduct the most comprehensive empirical study of post-hoc calibration to date. Our results reveal consistent patterns across domains: smooth calibration functions outperform binning-based approaches, dedicated multiclass methods are essential in high-dimensional settings, and generic machine learning models are not competitive without calibration-specific design. To facilitate future research, we release all data, code, and evaluation tools, providing a plug-and-play benchmark for developing and comparing calibration methods. less
By: Chen Henry Wu, Aditi Raghunathan
Self-improvement at scale has been a longstanding goal for reasoning models, and there are two natural places to do it: at test time, through verification-refinement (V-R) loops; and at training time, through self-training methods. Both are gated by the same bottleneck: the verifier. V-R loops stall when verifier scores inflate while accuracy stagnates, and when feedback is too generic to act on; self-training fails similarly when bad self-ge... more
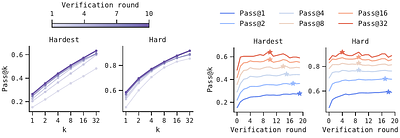
Self-improvement at scale has been a longstanding goal for reasoning models, and there are two natural places to do it: at test time, through verification-refinement (V-R) loops; and at training time, through self-training methods. Both are gated by the same bottleneck: the verifier. V-R loops stall when verifier scores inflate while accuracy stagnates, and when feedback is too generic to act on; self-training fails similarly when bad self-generated data are added to training. Better verification would unlock both, but the capability we want to train, i.e., catching self-generated errors, lacks training signal. To address this challenge, we propose self-trained verification (STV). Our key observation is that, while a model cannot catch these errors alone, it can when shown the reference solution. We turn this asymmetry into a supervision target and train the verifier to imitate a more informed version of itself. At test time, STV substantially improves V-R loops on hard problems, while alternatives (e.g., SFT, RL on verifier scores, and even meta-verifiers) do not. STV roughly doubles accuracy on hard math and lifts it 14x on scientific reasoning tasks (1.5% to 21%). At training time, we additionally train the generator using RL with STV verifier's feedback inside the V-R loop - a procedure we call verifier-in-the-loop training (ViL). Starting from an RL-converged generator, ViL yields a further 33% gain in pass@1. More notably, the generator's standalone pass@1, with no verifier at test time, climbs 30% relative past where standard RL had converged. Hence, the next frontier in reasoning on hard problems may lie in how we train for and with verification. less
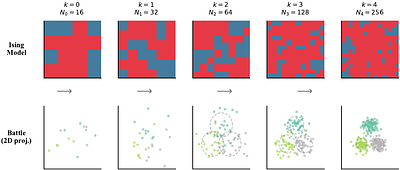
By: Wenhao Li, Xiangfeng Wang, Bo Jin
Diffusion-based planning has achieved strong results in single-agent offline reinforcement learning, yet scaling to many-agent systems remains intractable due to the curse of dimensionality in the joint trajectory space. We introduce MF-Diffuser, a framework that lifts trajectory planning to the Wasserstein space of trajectory distributions, where the propagation of chaos ensures a small representative subset of agents captures the full popul... more
Diffusion-based planning has achieved strong results in single-agent offline reinforcement learning, yet scaling to many-agent systems remains intractable due to the curse of dimensionality in the joint trajectory space. We introduce MF-Diffuser, a framework that lifts trajectory planning to the Wasserstein space of trajectory distributions, where the propagation of chaos ensures a small representative subset of agents captures the full population dynamics. Our approach features a value-weighted chaotic entropy objective that reconciles generative fidelity with return maximization, and a hierarchical coarse-to-fine strategy that progressively grows the agent population during denoising. We establish end-to-end suboptimality bounds with four interpretable terms, revealing that mean-field approximation error scales as $O(H^2/\sqrt{N})$ while offline distribution shift provably does not grow with population size $N$, and prove the generated policy is an approximate mean-field Nash equilibrium with explicit convergence guarantees. Experiments on three mean-field RL benchmarks -- spanning stage games, sequential dynamics, and adversarial team competition -- show MF-Diffuser achieves the best return in the majority of settings, with the largest gains on suboptimal offline data and at extreme scales ($N \geq 10^3$). less
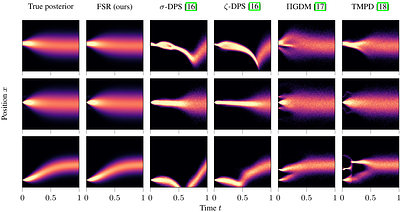
By: Benjamin A. Burns, Sara Fridovich-Keil
Diffusion models have excellent capacity to model complex distributions of natural data, which has made them a popular and effective choice for posterior sampling in imaging inverse problems. Existing methods can incorporate any measurement model at inference time but must use an inexact approximation for the likelihood at intermediate timesteps for computational tractability. Although these approximations can often work well empirically, the... more
Diffusion models have excellent capacity to model complex distributions of natural data, which has made them a popular and effective choice for posterior sampling in imaging inverse problems. Existing methods can incorporate any measurement model at inference time but must use an inexact approximation for the likelihood at intermediate timesteps for computational tractability. Although these approximations can often work well empirically, their downstream effect on the sampled posterior is poorly understood and can result in unexplained failures. To understand when, why, and how these likelihood approximations propagate to erroneous posterior distributions, we introduce a finite-sample perspective on posterior sampling that approximates the posterior to arbitrary precision as training set size tends towards infinity, for any forward model and prior distribution. Using this finite-sample lens, we observe that popular posterior sampling approximations tend to under- or over-estimate the spread of the posterior at intermediate timesteps, causing downstream consequences including sensitivity to early stopping time, inaccurate relative weighting of posterior modes, and hallucination, both of prior modes that are not in the posterior and likelihood modes that are not supported by the prior. Moreover, we find that the cause of these posterior errors requires neither a nonlinear measurement model nor a multimodal posterior, but can arise solely due to a multimodal prior and inaccurate posterior spread at intermediate sampling times. Our finite-sample posterior sampling approach is agnostic to the type of likelihood approximation and the type of (linear or nonlinear) forward model, and can thus serve as a drop-in diagnostic to evaluate the accuracy and failure modes of existing and future posterior samplers. less
By: Alaa Khamis, Alaa Maalouf
Test-time finetuning (TTFT) is a rapidly evolving paradigm that adapts a language model to each prompt by retrieving related sequences, updating the model on them, and then evaluating the prompt. However, TTFT is only practical if it is fast: selection and finetuning both happen per query, making each a direct bottleneck. Existing methods trade speed for quality: fast retrieval is often redundant, while stronger diversity-aware selection adds... more
Test-time finetuning (TTFT) is a rapidly evolving paradigm that adapts a language model to each prompt by retrieving related sequences, updating the model on them, and then evaluating the prompt. However, TTFT is only practical if it is fast: selection and finetuning both happen per query, making each a direct bottleneck. Existing methods trade speed for quality: fast retrieval is often redundant, while stronger diversity-aware selection adds prohibitive per-query cost. We introduce HullFT, a geometric approach to TTFT that addresses both bottlenecks. Given a query, HullFT first represents the query embedding as a sparse convex combination of few training sequences, using efficient projection-free Frank-Wolfe optimization. This yields a support set that is inherently relevant and diverse. We then convert the fractional convex weights into an exact integer multiset for finetuning through a geometric integerization procedure. The resulting multiplicities naturally create repeated examples, which we exploit with Gradient Reuse to amortize forward-backward computation across repeated finetuning steps. Our experiments show that HullFT improves the quality-efficiency tradeoff over current state-of-the-art TTFT methods, achieving lower bits-per-byte at substantially lower total runtime. less
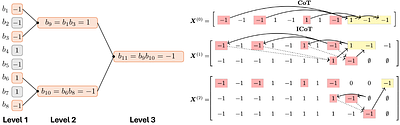
By: Yixiao Huang, Hanlin Zhu, Zixuan Wang, Jiantao Jiao, Stuart Russell, Somayeh Sojoudi, Song Mei
Chain-of-Thought (CoT) prompting substantially improves the sample efficiency of transformers, reducing the complexity of tasks like parity learning from exponential to polynomial in the input length. However, generating explicit reasoning steps at inference is computationally expensive. Implicit Chain-of-Thought (ICoT) has emerged as a promising empirical remedy that trains models to internalize intermediate steps within their hidden states,... more
Chain-of-Thought (CoT) prompting substantially improves the sample efficiency of transformers, reducing the complexity of tasks like parity learning from exponential to polynomial in the input length. However, generating explicit reasoning steps at inference is computationally expensive. Implicit Chain-of-Thought (ICoT) has emerged as a promising empirical remedy that trains models to internalize intermediate steps within their hidden states, but its theoretical foundations remain poorly understood. We give the first theoretical analysis of ICoT, proving that an $L$-layer transformer trained under our proposed Log-ICoT curriculum learns $k$-parity with $\mathsf{poly}(n)$ samples and $L = \log_2 k$ training stages. This matches the sample efficiency of explicit CoT while eliminating its inference overhead, and extends prior one-layer parity guarantees to multi-layer architectures. Compared to standard ICoT, which removes thinking tokens one at a time, Log-ICoT removes them in geometric chunks, reducing the number of stages from linear in $k$ to logarithmic. Experiments on multi-layer transformers confirm the theory and visualize how reasoning is progressively absorbed into deeper layers. less
By: Kevin Y. Li, Asher Trockman, Ananda Theertha Suresh, Ziteng Sun
Softmax attention is the cornerstone of modern large language models, but its memory scales linearly and compute quadratically with sequence length. Linear recurrent models, such as linear attention and state space models, have become widely studied as alternatives to attention due to their linear compute and constant memory. While these sub-quadratic token mixing methods, or mixers, achieve promising efficiency gains and competitive results ... more
Softmax attention is the cornerstone of modern large language models, but its memory scales linearly and compute quadratically with sequence length. Linear recurrent models, such as linear attention and state space models, have become widely studied as alternatives to attention due to their linear compute and constant memory. While these sub-quadratic token mixing methods, or mixers, achieve promising efficiency gains and competitive results on a wide range of benchmarks, current linear recurrent models still lag behind on tasks that require long-context retrieval or in-context learning. A growing body of work studies hybrid architectures that attempt to mitigate these trade-offs by statically interleaving or merging attention and recurrent blocks. In this work, we explore a new axis of developing hybrid models: across the token sequence. We propose Oryx, a hybrid model that can, throughout a sequence, flexibly switch between different mixers, for example quadratic attention for rich context utilization and linear recurrences for efficient generation. Oryx ties at least 90% of its parameters across mixers, enabling attention and recurrent modes to operate over shared internal representations. We validate our design with Mamba-2 and Gated DeltaNet variants, up to 1.4B models. Under fixed token budgets and a mixed-training strategy, Oryx achieves comparable or better performance than its single-mixer baselines. At the 1.4B scale, all instances of Oryx outperform their respective baselines by at least 0.7 percentage points on averaged language modeling tasks. On retrieval tasks, Oryx achieves performance comparable to the Transformer baseline even when processing only a tiny fraction (<10%) of the tokens in attention mode. These results suggest that attention and linear recurrent models can share internal representations, and motivate sequence-axis hybridization as a promising direction. less
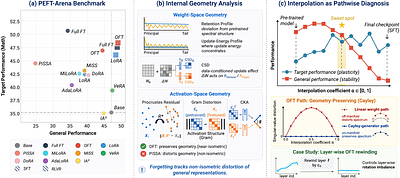
PEFT-Arena: Understanding Parameter-Efficient Finetuning from a Stability-Plasticity Perspective
0upvotes
By: Yangyi Huang, Ruotian Peng, Zeju Qiu, Jiale Kang, Yandong Wen, Bernhard Schölkopf, Weiyang Liu
Parameter-efficient finetuning (PEFT) has become the standard approach for adapting large language models, yet evaluations largely emphasize downstream accuracy while overlooking the retention of pretrained capabilities. We argue that PEFT should be assessed through the stability-plasticity dilemma: the trade-off between target-task adaptation and resistance to forgetting. We introduce PEFT-Arena, a benchmark that jointly measures downstream ... more
Parameter-efficient finetuning (PEFT) has become the standard approach for adapting large language models, yet evaluations largely emphasize downstream accuracy while overlooking the retention of pretrained capabilities. We argue that PEFT should be assessed through the stability-plasticity dilemma: the trade-off between target-task adaptation and resistance to forgetting. We introduce PEFT-Arena, a benchmark that jointly measures downstream performance and general capability retention. Across methods, we find distinct stability-plasticity profiles; under comparable parameter budgets, orthogonal finetuning achieves the most favorable Pareto frontier. To explain these differences, we analyze PEFT updates from two geometric perspectives. In weight space, spectral analysis reveals how parameterizations interact with the pretrained singular-value structure. In activation space, retention metrics show whether finetuning preserves or distorts general-capability representations, with forgetting linked to non-isometric representation distortion. Finally, an analysis shows that final SFT checkpoints often overshoot a better target-retention operating point. Inspired by this, we present case studies of a post-hoc improvement with path-wise rewinding. less