By: Peixuan Han, Zhenghao Liu, Zhiyuan Liu, Chenyan Xiong
This paper introduces Web-DRO, an unsupervised dense retrieval model, which clusters documents based on web structures and reweights the groups during contrastive training. Specifically, we first leverage web graph links and contrastively train an embedding model for clustering anchor-document pairs. Then we use Group Distributional Robust Optimization to reweight different clusters of anchor-document pairs, which guides the model to assign... more
This paper introduces Web-DRO, an unsupervised dense retrieval model, which clusters documents based on web structures and reweights the groups during contrastive training. Specifically, we first leverage web graph links and contrastively train an embedding model for clustering anchor-document pairs. Then we use Group Distributional Robust Optimization to reweight different clusters of anchor-document pairs, which guides the model to assign more weights to the group with higher contrastive loss and pay more attention to the worst case during training. Our experiments on MS MARCO and BEIR show that our model, Web-DRO, significantly improves the retrieval effectiveness in unsupervised scenarios. A comparison of clustering techniques shows that training on the web graph combining URL information reaches optimal performance on clustering. Further analysis confirms that group weights are stable and valid, indicating consistent model preferences as well as effective up-weighting of valuable groups and down-weighting of uninformative ones. The code of this paper can be obtained from https://github.com/OpenMatch/Web-DRO. less
By: Liang Wang, Nan Yang, Xiaolong Huang, Linjun Yang, Rangan Majumder, Furu Wei
Modern search engines are built on a stack of different components, including query understanding, retrieval, multi-stage ranking, and question answering, among others. These components are often optimized and deployed independently. In this paper, we introduce a novel conceptual framework called large search model, which redefines the conventional search stack by unifying search tasks with one large language model (LLM). All tasks are form... more
Modern search engines are built on a stack of different components, including query understanding, retrieval, multi-stage ranking, and question answering, among others. These components are often optimized and deployed independently. In this paper, we introduce a novel conceptual framework called large search model, which redefines the conventional search stack by unifying search tasks with one large language model (LLM). All tasks are formulated as autoregressive text generation problems, allowing for the customization of tasks through the use of natural language prompts. This proposed framework capitalizes on the strong language understanding and reasoning capabilities of LLMs, offering the potential to enhance search result quality while simultaneously simplifying the existing cumbersome search stack. To substantiate the feasibility of this framework, we present a series of proof-of-concept experiments and discuss the potential challenges associated with implementing this approach within real-world search systems. less

By: Yunke Qu, Tong Chen, Quoc Viet Hung Nguyen, Hongzhi Yin
At the heart of contemporary recommender systems (RSs) are latent factor models that provide quality recommendation experience to users. These models use embedding vectors, which are typically of a uniform and fixed size, to represent users and items. As the number of users and items continues to grow, this design becomes inefficient and hard to scale. Recent lightweight embedding methods have enabled different users and items to have diver... more
At the heart of contemporary recommender systems (RSs) are latent factor models that provide quality recommendation experience to users. These models use embedding vectors, which are typically of a uniform and fixed size, to represent users and items. As the number of users and items continues to grow, this design becomes inefficient and hard to scale. Recent lightweight embedding methods have enabled different users and items to have diverse embedding sizes, but are commonly subject to two major drawbacks. Firstly, they limit the embedding size search to optimizing a heuristic balancing the recommendation quality and the memory complexity, where the trade-off coefficient needs to be manually tuned for every memory budget requested. The implicitly enforced memory complexity term can even fail to cap the parameter usage, making the resultant embedding table fail to meet the memory budget strictly. Secondly, most solutions, especially reinforcement learning based ones derive and optimize the embedding size for each each user/item on an instance-by-instance basis, which impedes the search efficiency. In this paper, we propose Budgeted Embedding Table (BET), a novel method that generates table-level actions (i.e., embedding sizes for all users and items) that is guaranteed to meet pre-specified memory budgets. Furthermore, by leveraging a set-based action formulation and engaging set representation learning, we present an innovative action search strategy powered by an action fitness predictor that efficiently evaluates each table-level action. Experiments have shown state-of-the-art performance on two real-world datasets when BET is paired with three popular recommender models under different memory budgets. less
By: Mingdai Yang, Zhiwei Liu, Liangwei Yang, Xiaolong Liu, Chen Wang, Hao Peng, Philip S. Yu
Although pretraining has garnered significant attention and popularity in recent years, its application in graph-based recommender systems is relatively limited. It is challenging to exploit prior knowledge by pretraining in widely used ID-dependent datasets. On one hand, user-item interaction history in one dataset can hardly be transferred to other datasets through pretraining, where IDs are different. On the other hand, pretraining and f... more
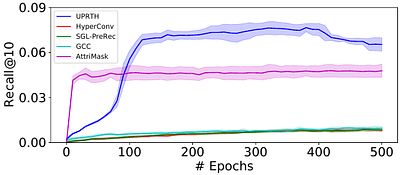
Although pretraining has garnered significant attention and popularity in recent years, its application in graph-based recommender systems is relatively limited. It is challenging to exploit prior knowledge by pretraining in widely used ID-dependent datasets. On one hand, user-item interaction history in one dataset can hardly be transferred to other datasets through pretraining, where IDs are different. On the other hand, pretraining and finetuning on the same dataset leads to a high risk of overfitting. In this paper, we propose a novel multitask pretraining framework named Unified Pretraining for Recommendation via Task Hypergraphs. For a unified learning pattern to handle diverse requirements and nuances of various pretext tasks, we design task hypergraphs to generalize pretext tasks to hyperedge prediction. A novel transitional attention layer is devised to discriminatively learn the relevance between each pretext task and recommendation. Experimental results on three benchmark datasets verify the superiority of UPRTH. Additional detailed investigations are conducted to demonstrate the effectiveness of the proposed framework. less
By: Bowen Hao, Chaoqun Yang, Lei Guo, Junliang Yu, Hongzhi Yin
Cross-Domain Recommendation (CDR) stands as a pivotal technology addressing issues of data sparsity and cold start by transferring general knowledge from the source to the target domain. However, existing CDR models suffer limitations in adaptability across various scenarios due to their inherent complexity. To tackle this challenge, recent advancements introduce universal CDR models that leverage shared embeddings to capture general knowle... more
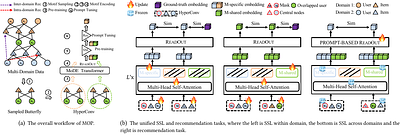
Cross-Domain Recommendation (CDR) stands as a pivotal technology addressing issues of data sparsity and cold start by transferring general knowledge from the source to the target domain. However, existing CDR models suffer limitations in adaptability across various scenarios due to their inherent complexity. To tackle this challenge, recent advancements introduce universal CDR models that leverage shared embeddings to capture general knowledge across domains and transfer it through "Multi-task Learning" or "Pre-train, Fine-tune" paradigms. However, these models often overlook the broader structural topology that spans domains and fail to align training objectives, potentially leading to negative transfer. To address these issues, we propose a motif-based prompt learning framework, MOP, which introduces motif-based shared embeddings to encapsulate generalized domain knowledge, catering to both intra-domain and inter-domain CDR tasks. Specifically, we devise three typical motifs: butterfly, triangle, and random walk, and encode them through a Motif-based Encoder to obtain motif-based shared embeddings. Moreover, we train MOP under the "Pre-training \& Prompt Tuning" paradigm. By unifying pre-training and recommendation tasks as a common motif-based similarity learning task and integrating adaptable prompt parameters to guide the model in downstream recommendation tasks, MOP excels in transferring domain knowledge effectively. Experimental results on four distinct CDR tasks demonstrate the effectiveness of MOP than the state-of-the-art models. less
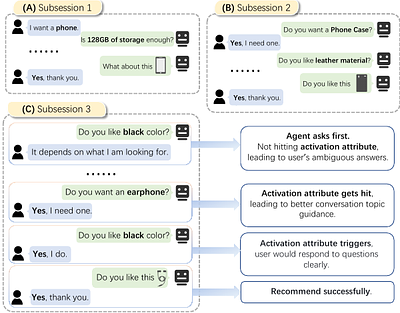
By: Yu Ji, Qi Shen, Shixuan Zhu, Hang Yu, Yiming Zhang, Chuan Cui, Zhihua Wei
Conversational recommendation systems (CRS) could acquire dynamic user preferences towards desired items through multi-round interactive dialogue. Previous CRS mainly focuses on the single conversation (subsession) that user quits after a successful recommendation, neglecting the common scenario where user has multiple conversations (multi-subsession) over a short period. Therefore, we propose a novel conversational recommendation scenario ... more
Conversational recommendation systems (CRS) could acquire dynamic user preferences towards desired items through multi-round interactive dialogue. Previous CRS mainly focuses on the single conversation (subsession) that user quits after a successful recommendation, neglecting the common scenario where user has multiple conversations (multi-subsession) over a short period. Therefore, we propose a novel conversational recommendation scenario named Multi-Subsession Multi-round Conversational Recommendation (MSMCR), where user would still resort to CRS after several subsessions and might preserve vague interests, and system would proactively ask attributes to activate user interests in the current subsession. To fill the gap in this new CRS scenario, we devise a novel framework called Multi-Subsession Conversational Recommender with Activation Attributes (MSCAA). Specifically, we first develop a context-aware recommendation module, comprehensively modeling user interests from historical interactions, previous subsessions, and feedback in the current subsession. Furthermore, an attribute selection policy module is proposed to learn a flexible strategy for asking appropriate attributes to elicit user interests. Finally, we design a conversation policy module to manage the above two modules to decide actions between asking and recommending. Extensive experiments on four datasets verify the effectiveness of our MSCAA framework for the MSMCR setting. less
By: Zekai Qu, Ruobing Xie, Chaojun Xiao, Yuan Yao, Zhiyuan Liu, Fengzong Lian, Zhanhui Kang, Jie Zhou
With the thriving of pre-trained language model (PLM) widely verified in various of NLP tasks, pioneer efforts attempt to explore the possible cooperation of the general textual information in PLM with the personalized behavioral information in user historical behavior sequences to enhance sequential recommendation (SR). However, despite the commonalities of input format and task goal, there are huge gaps between the behavioral and textual ... more
With the thriving of pre-trained language model (PLM) widely verified in various of NLP tasks, pioneer efforts attempt to explore the possible cooperation of the general textual information in PLM with the personalized behavioral information in user historical behavior sequences to enhance sequential recommendation (SR). However, despite the commonalities of input format and task goal, there are huge gaps between the behavioral and textual information, which obstruct thoroughly modeling SR as language modeling via PLM. To bridge the gap, we propose a novel Unified pre-trained language model enhanced sequential recommendation (UPSR), aiming to build a unified pre-trained recommendation model for multi-domain recommendation tasks. We formally design five key indicators, namely naturalness, domain consistency, informativeness, noise & ambiguity, and text length, to guide the text->item adaptation and behavior sequence->text sequence adaptation differently for pre-training and fine-tuning stages, which are essential but under-explored by previous works. In experiments, we conduct extensive evaluations on seven datasets with both tuning and zero-shot settings and achieve the overall best performance. Comprehensive model analyses also provide valuable insights for behavior modeling via PLM, shedding light on large pre-trained recommendation models. The source codes will be released in the future. less
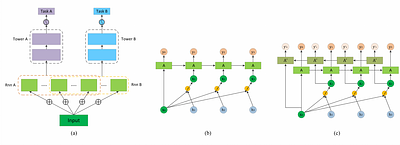
DCRNN: A Deep Cross approach based on RNN for Partial Parameter Sharing in Multi-task Learning
0upvotes
By: Jie Zhou, Qian Yu
In recent years, DL has developed rapidly, and personalized services are exploring using DL algorithms to improve the performance of the recommendation system. For personalized services, a successful recommendation consists of two parts: attracting users to click the item and users being willing to consume the item. If both tasks need to be predicted at the same time, traditional recommendation systems generally train two independent models... more
In recent years, DL has developed rapidly, and personalized services are exploring using DL algorithms to improve the performance of the recommendation system. For personalized services, a successful recommendation consists of two parts: attracting users to click the item and users being willing to consume the item. If both tasks need to be predicted at the same time, traditional recommendation systems generally train two independent models. This approach is cumbersome and does not effectively model the relationship between the two subtasks of "click-consumption". Therefore, in order to improve the success rate of recommendation and reduce computational costs, researchers are trying to model multi-task learning. At present, existing multi-task learning models generally adopt hard parameter sharing or soft parameter sharing architecture, but these two architectures each have certain problems. Therefore, in this work, we propose a novel recommendation model based on real recommendation scenarios, Deep Cross network based on RNN for partial parameter sharing (DCRNN). The model has three innovations: 1) It adopts the idea of cross network and uses RNN network to cross-process the features, thereby effectively improves the expressive ability of the model; 2) It innovatively proposes the structure of partial parameter sharing; 3) It can effectively capture the potential correlation between different tasks to optimize the efficiency and methods for learning different tasks. less
CIR at the NTCIR-17 ULTRE-2 Task
0upvotes
By: Lulu Yu, Keping Bi, Jiafeng Guo, Xueqi Cheng
The Chinese academy of sciences Information Retrieval team (CIR) has participated in the NTCIR-17 ULTRE-2 task. This paper describes our approaches and reports our results on the ULTRE-2 task. We recognize the issue of false negatives in the Baidu search data in this competition is very severe, much more severe than position bias. Hence, we adopt the Dual Learning Algorithm (DLA) to address the position bias and use it as an auxiliary model... more
The Chinese academy of sciences Information Retrieval team (CIR) has participated in the NTCIR-17 ULTRE-2 task. This paper describes our approaches and reports our results on the ULTRE-2 task. We recognize the issue of false negatives in the Baidu search data in this competition is very severe, much more severe than position bias. Hence, we adopt the Dual Learning Algorithm (DLA) to address the position bias and use it as an auxiliary model to study how to alleviate the false negative issue. We approach the problem from two perspectives: 1) correcting the labels for non-clicked items by a relevance judgment model trained from DLA, and learn a new ranker that is initialized from DLA; 2) including random documents as true negatives and documents that have partial matching as hard negatives. Both methods can enhance the model performance and our best method has achieved nDCG@10 of 0.5355, which is 2.66% better than the best score from the organizer. less
By: Björn Engelmann, Timo Breuer, Philipp Schaer
Considering the multimodal signals of search items is beneficial for retrieval effectiveness. Especially in web table retrieval (WTR) experiments, accounting for multimodal properties of tables boosts effectiveness. However, it still remains an open question how the single modalities affect user experience in particular. Previous work analyzed WTR performance in ad-hoc retrieval benchmarks, which neglects interactive search behavior and lim... more
Considering the multimodal signals of search items is beneficial for retrieval effectiveness. Especially in web table retrieval (WTR) experiments, accounting for multimodal properties of tables boosts effectiveness. However, it still remains an open question how the single modalities affect user experience in particular. Previous work analyzed WTR performance in ad-hoc retrieval benchmarks, which neglects interactive search behavior and limits the conclusion about the implications for real-world user environments. To this end, this work presents an in-depth evaluation of simulated interactive WTR search sessions as a more cost-efficient and reproducible alternative to real user studies. As a first of its kind, we introduce interactive query reformulation strategies based on Doc2Query, incorporating cognitive states of simulated user knowledge. Our evaluations include two perspectives on user effectiveness by considering different cost paradigms, namely query-wise and time-oriented measures of effort. Our multi-perspective evaluation scheme reveals new insights about query strategies, the impact of modalities, and different user types in simulated WTR search sessions. less