By: Carsten Eickhoff
An increasing number of CS researchers are employed in academic non-CS departments where publication output is measured in terms of journal impact factors. To foster recognition of publications in peer-reviewed CS conference proceedings, we analyzed more than 40,000 CS publications and computed journal impact factors for 88 top-ranking conferences across a representative range of fields, finding that some conferences have impact factors cor... more
An increasing number of CS researchers are employed in academic non-CS departments where publication output is measured in terms of journal impact factors. To foster recognition of publications in peer-reviewed CS conference proceedings, we analyzed more than 40,000 CS publications and computed journal impact factors for 88 top-ranking conferences across a representative range of fields, finding that some conferences have impact factors corresponding to those of high-ranking journals. less

By: Giacomo Alliata, Sarah Kenderdine, Lily Hibberd, Ingrid Mason
This article proposes an innovative framework to explore large audiovisual archives using Immersive Environments to place users inside a dataset and create an embodied experience. It starts by outlining the need for such a novel interface to meet the needs of archival scholars and the GLAM sector, and discusses issues in the current modes of access, mostly restrained to traditional information retrieval systems based on metadata. The paper ... more
This article proposes an innovative framework to explore large audiovisual archives using Immersive Environments to place users inside a dataset and create an embodied experience. It starts by outlining the need for such a novel interface to meet the needs of archival scholars and the GLAM sector, and discusses issues in the current modes of access, mostly restrained to traditional information retrieval systems based on metadata. The paper presents the concept of ``generous interfaces" as a preliminary approach to address these issues, and argues some of the key reasons why employing Immersive Visual Storytelling might benefit such frameworks. The theory of embodiment is leveraged to justify this claim, showing how a more embodied understanding of a collection can result in a stronger engagement for the public. By placing users as actors in the experience rather than mere spectators, the emergence of narrative is driven by their interactions, with benefits in terms of engagement with the public and understanding of the cultural component. The framework we propose is applied to two existing installations to analyze them in-depth and critique them, highlighting the key directions to pursue for further development. less

By: Swathi Anil, Jennifer D'Souza
Noninvasive brain stimulation (NIBS) encompasses transcranial stimulation techniques that can influence brain excitability. These techniques have the potential to treat conditions like depression, anxiety, and chronic pain, and to provide insights into brain function. However, a lack of standardized reporting practices limits its reproducibility and full clinical potential. This paper aims to foster interinterdisciplinarity toward adopting ... more
Noninvasive brain stimulation (NIBS) encompasses transcranial stimulation techniques that can influence brain excitability. These techniques have the potential to treat conditions like depression, anxiety, and chronic pain, and to provide insights into brain function. However, a lack of standardized reporting practices limits its reproducibility and full clinical potential. This paper aims to foster interinterdisciplinarity toward adopting Computer Science Semantic reporting methods for the standardized documentation of Neuroscience NIBS studies making them explicitly Findable, Accessible, Interoperable, and Reusable (FAIR). In a large-scale systematic review of 600 repetitive transcranial magnetic stimulation (rTMS), a subarea of NIBS, dosages, we describe key properties that allow for structured descriptions and comparisons of the studies. This paper showcases the semantic publishing of NIBS in the ecosphere of knowledge-graph-based next-generation scholarly digital libraries. Specifically, the FAIR Semantic Web resource(s)-based publishing paradigm is implemented for the 600 reviewed rTMS studies in the Open Research Knowledge Graph. less
By: Dorothea Strecker, Heinz Pampel, Rouven Schabinger, Nina Leonie Weisweiler
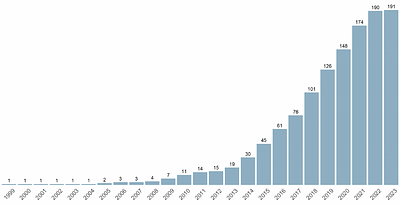
Currently, there is limited research investigating the phenomenon of research data repositories being shut down, and the impact this has on the long-term availability of data. This paper takes an infrastructure perspective on the preservation of research data by using a registry to identify 191 research data repositories that have been closed and presenting information on the shutdown process. The results show that 6.2 % of research data re... more
Currently, there is limited research investigating the phenomenon of research data repositories being shut down, and the impact this has on the long-term availability of data. This paper takes an infrastructure perspective on the preservation of research data by using a registry to identify 191 research data repositories that have been closed and presenting information on the shutdown process. The results show that 6.2 % of research data repositories indexed in the registry were shut down. The risks resulting in repository shutdown are varied. The median age of a repository when shutting down is 12 years. Strategies to prevent data loss at the infrastructure level are pursued to varying extent. 44 % of the repositories in the sample migrated data to another repository, and 12 % maintain limited access to their data collection. However, both strategies are not permanent solutions. Finally, the general lack of information on repository shutdown events as well as the effect on the findability of data and the permanence of the scholarly record are discussed. less

By: Lonni Besançon, Guillaume Cabanac, Cyril Labbé, Alexander Magazinov
We report evidence of an undocumented method to manipulate citation counts involving 'sneaked' references. Sneaked references are registered as metadata for scientific articles in which they do not appear. This manipulation exploits trusted relationships between various actors: publishers, the Crossref metadata registration agency, digital libraries, and bibliometric platforms. By collecting metadata from various sources, we show that extra... more
We report evidence of an undocumented method to manipulate citation counts involving 'sneaked' references. Sneaked references are registered as metadata for scientific articles in which they do not appear. This manipulation exploits trusted relationships between various actors: publishers, the Crossref metadata registration agency, digital libraries, and bibliometric platforms. By collecting metadata from various sources, we show that extra undue references are actually sneaked in at Digital Object Identifier (DOI) registration time, resulting in artificially inflated citation counts. As a case study, focusing on three journals from a given publisher, we identified at least 9% sneaked references (5,978/65,836) mainly benefiting two authors. Despite not existing in the articles, these sneaked references exist in metadata registries and inappropriately propagate to bibliometric dashboards. Furthermore, we discovered 'lost' references: the studied bibliometric platform failed to index at least 56% (36,939/65,836) of the references listed in the HTML version of the publications. The extent of the sneaked and lost references in the global literature remains unknown and requires further investigations. Bibliometric platforms producing citation counts should identify, quantify, and correct these flaws to provide accurate data to their patrons and prevent further citation gaming. less
By: Shamsi Brinn, Christopher Cameron, David Fielding, Charles Frankston, Alison Fromme, Peter Huang, Mark Nazzaro, Stephanie Orphan, Steinn Sigurdsson, Ryan Tay, Miranda Yang, Qianyu Zhou
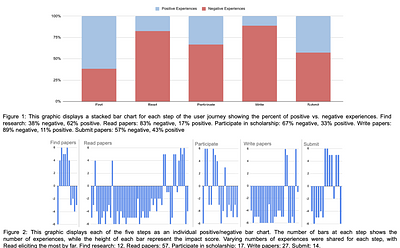
The research content hosted by arXiv is not fully accessible to everyone due
to disabilities and other barriers. This matters because a significant
proportion of people have reading and visual disabilities, it is important to
our community that arXiv is as open as possible, and if science is to advance,
we need wide and diverse participation. In addition, we have mandates to become
accessible, and accessible content benefits everyone. In this... more
The research content hosted by arXiv is not fully accessible to everyone due
to disabilities and other barriers. This matters because a significant
proportion of people have reading and visual disabilities, it is important to
our community that arXiv is as open as possible, and if science is to advance,
we need wide and diverse participation. In addition, we have mandates to become
accessible, and accessible content benefits everyone. In this paper, we will
describe the accessibility problems with research, review current mitigations
(and explain why they aren't sufficient), and share the results of our user
research with scientists and accessibility experts. Finally, we will present
arXiv's proposed next step towards more open science: offering HTML alongside
existing PDF and TeX formats. An accessible HTML version of this paper is also
available at https://info.arxiv.org/about/accessibility_research_report.html
less
By: Kaushik Ghosh, Mayukh Mukhopadhyay
The current discourse delves into the effectiveness of h-index as an author
level metric. It further reviews and explains the algorithmic complexity of
calculating h-index through algebraic method. To conduct the algebraic analysis
propositional algebra, algorithm and coding techniques have been used. Some use
cases have been identified with a finite-data-set/set-of-array to demonstrate
the coding techniques and for further analysis. Finall... more
The current discourse delves into the effectiveness of h-index as an author
level metric. It further reviews and explains the algorithmic complexity of
calculating h-index through algebraic method. To conduct the algebraic analysis
propositional algebra, algorithm and coding techniques have been used. Some use
cases have been identified with a finite-data-set/set-of-array to demonstrate
the coding techniques and for further analysis. Finally, the explanation and
calculative complexities to determine the index have been further simplified
through geometric method of calculating the h-index using the similar use cases
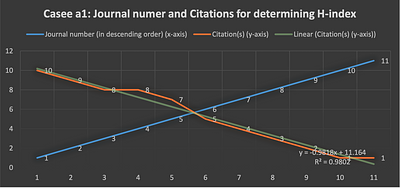
that was used for coding. It is concluded that determination of the h-index
using Euclidean geometric method with Cartesian frame of reference provides a
through and visual clarification. Finally, a set of postulates has been
proposed at the end of the paper, based on the case studies.
less