By: Zhenhang Yuan, Shenghai Yuan, Lihua Xie
LLM agents often fail in closed-world embodied environments because actions must satisfy strict preconditions -- such as location, inventory, and container states -- and failure feedback is sparse. We identify two structurally coupled failure modes: (P1) invalid action generation and (P2) state drift, each amplifying the other in a degenerative cycle. We present RPMS, a conflict-managed architecture that enforces action feasibility via struct... more
LLM agents often fail in closed-world embodied environments because actions must satisfy strict preconditions -- such as location, inventory, and container states -- and failure feedback is sparse. We identify two structurally coupled failure modes: (P1) invalid action generation and (P2) state drift, each amplifying the other in a degenerative cycle. We present RPMS, a conflict-managed architecture that enforces action feasibility via structured rule retrieval, gates memory applicability via a lightweight belief state, and resolves conflicts between the two sources via rules-first arbitration. On ALFWorld (134 unseen tasks), RPMS achieves 59.7% single-trial success with Llama 3.1 8B (+23.9 pp over baseline) and 98.5% with Claude Sonnet 4.5 (+11.9 pp); of the 8B gain, rule retrieval alone contributes +14.9 pp (statistically significant), making it the dominant factor. A key finding is that episodic memory is conditionally useful: it harms performance on some task types when used without grounding, but becomes a stable net positive once filtered by current state and constrained by explicit action rules. Adapting RPMS to ScienceWorld with GPT-4 yields consistent gains across all ablation conditions (avg. score 54.0 vs. 44.9 for the ReAct baseline), providing transfer evidence that the core mechanisms hold across structurally distinct environments. less
By: Zhang Zhang, Shuqi Lu, Hongjin Qian, Di He, Zheng Liu
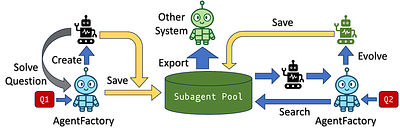
Building LLM-based agents has become increasingly important. Recent works on LLM-based agent self-evolution primarily record successful experiences as textual prompts or reflections, which cannot reliably guarantee efficient task re-execution in complex scenarios. We propose AgentFactory, a new self-evolution paradigm that preserves successful task solutions as executable subagent code rather than textual experience. Crucially, these subagent... more
Building LLM-based agents has become increasingly important. Recent works on LLM-based agent self-evolution primarily record successful experiences as textual prompts or reflections, which cannot reliably guarantee efficient task re-execution in complex scenarios. We propose AgentFactory, a new self-evolution paradigm that preserves successful task solutions as executable subagent code rather than textual experience. Crucially, these subagents are continuously refined based on execution feedback, becoming increasingly robust and efficient as more tasks are encountered. Saved subagents are pure Python code with standardized documentation, enabling portability across any Python-capable system. We demonstrate that AgentFactory enables continuous capability accumulation: its library of executable subagents grows and improves over time, progressively reducing the effort required for similar tasks without manual intervention. Our implementation is open-sourced at https://github.com/zzatpku/AgentFactory, and our demonstration video is available at https://youtu.be/iKSsuAXJHW0. less
By: Yi Nian, Haosen Cao, Shenzhe Zhu, Henry Peng Zou, Qingqing Luan, Yue Zhao
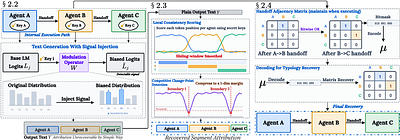
When a multi-agent system produces an incorrect or harmful answer, who is accountable if execution logs and agent identifiers are unavailable? Multi-agent language systems increasingly rely on structured interactions such as delegation and iterative refinement, yet the final output often obscures the underlying interaction topology and agent contributions. We introduce IET (Implicit Execution Tracing), a metadata-independent framework that en... more
When a multi-agent system produces an incorrect or harmful answer, who is accountable if execution logs and agent identifiers are unavailable? Multi-agent language systems increasingly rely on structured interactions such as delegation and iterative refinement, yet the final output often obscures the underlying interaction topology and agent contributions. We introduce IET (Implicit Execution Tracing), a metadata-independent framework that enables token-level attribution directly from generated text and a simple mechanism for interaction topology reconstruction. During generation, agent-specific keyed signals are embedded into the token distribution, transforming the text into a self-describing execution trace detectable only with a secret key. At detection time, a transition-aware scoring method identifies agent handover points and reconstructs the interaction graph. Experiments show that IET recovers agent segments and coordination structure with high accuracy while preserving generation quality, enabling privacy-preserving auditing for multi-agent language systems. less
By: Haozheng Luo, Yimin Wang, Jiahao Yu, Binghui Wang, Yan Chen
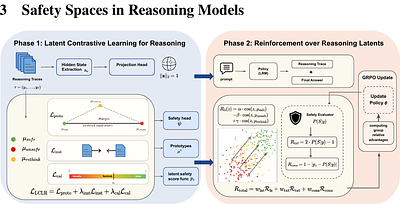
We propose CRAFT, a red-teaming alignment framework that leverages model reasoning capabilities and hidden representations to improve robustness against jailbreak attacks. Unlike prior defenses that operate primarily at the output level, CRAFT aligns large reasoning models to generate safety-aware reasoning traces by explicitly optimizing objectives defined over the hidden state space. Methodologically, CRAFT integrates contrastive representa... more
We propose CRAFT, a red-teaming alignment framework that leverages model reasoning capabilities and hidden representations to improve robustness against jailbreak attacks. Unlike prior defenses that operate primarily at the output level, CRAFT aligns large reasoning models to generate safety-aware reasoning traces by explicitly optimizing objectives defined over the hidden state space. Methodologically, CRAFT integrates contrastive representation learning with reinforcement learning to separate safe and unsafe reasoning trajectories, yielding a latent-space geometry that supports robust, reasoning-level safety alignment. Theoretically, we show that incorporating latent-textual consistency into GRPO eliminates superficially aligned policies by ruling them out as local optima. Empirically, we evaluate CRAFT on multiple safety benchmarks using two strong reasoning models, Qwen3-4B-Thinking and R1-Distill-Llama-8B, where it consistently outperforms state-of-the-art defenses such as IPO and SafeKey. Notably, CRAFT delivers an average 79.0% improvement in reasoning safety and 87.7% improvement in final-response safety over the base models, demonstrating the effectiveness of hidden-space reasoning alignment. less

By: Jianan Chen, Zhifang Zhang, Shuo He, Linan Yue, Lei Feng, Minling Zhang
Large reasoning models (LRMs) achieved remarkable performance via chain-of-thought (CoT), but recent studies showed that such enhanced reasoning capabilities are at the expense of significantly degraded safety capabilities. In this paper, we reveal that LRMs' safety degradation occurs only after CoT is enabled, and this degradation is not observed when CoT is disabled. This observation motivates us to consider encouraging LRMs to make safety ... more
Large reasoning models (LRMs) achieved remarkable performance via chain-of-thought (CoT), but recent studies showed that such enhanced reasoning capabilities are at the expense of significantly degraded safety capabilities. In this paper, we reveal that LRMs' safety degradation occurs only after CoT is enabled, and this degradation is not observed when CoT is disabled. This observation motivates us to consider encouraging LRMs to make safety decisions before CoT generation. To this end, we propose a novel safety alignment method that promotes the safety decision-making of LRMs before starting CoT generation. Specifically, we first utilize a Bert-based classifier to extract safety decision signals from a safe model (e.g., a CoT-disabled LRM) and then integrate these signals into LRMs' safety alignment as auxiliary supervision. In this way, the safety gradients can be backpropagated to the LRMs' latent representations, effectively strengthening the LRMs' safety decision-making abilities against CoT generation. Extensive experiments demonstrate that our method substantially improves the safety capabilities of LRMs while effectively maintaining LRMs' general reasoning performance. less
6 SciCasts by .