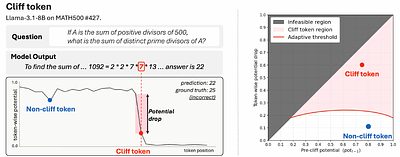
By: Jaeyong Ko, Pilsung Kang, Yukyung Lee

By: Hyejun Jeong, Dzung Pham, Amir Houmansadr, Eugene Bagdasarian
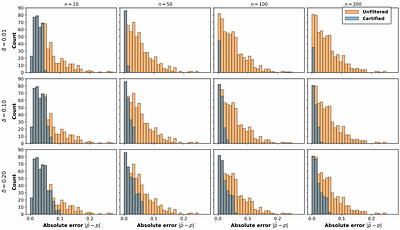
By: Konstantin Kueffner, Tobias Meggendorfer, Maximilian Weininger, Patrick Wienhöft
By: Peter Toth
By: Yikai Lu, Yifei Wu, Xinyu Lu, Tongxin Li

By: Negin Raoof, Richard Zhuang, Marianna Nezhurina, Etash Guha, Atula Tejaswi, Ryan Marten, Charlie F. Ruan, Tyler Griggs, Alexander Glenn Shaw, Hritik Bansal, E. Kelly Buchanan, Artem Gazizov, Reinhard Heckel, Chinmay Hegde, Sankalp Jajee, Daanish Khazi, Emmanouil Koukoumidis, Xiangyi Li, Hange Liu, Shlok Natarajan, Harsh Raj, Nicholas Roberts, Ethan Shen, Nishad Singhi, Michael Siu, Ashima Suvarna, Hanwen Xing, Patrick Yubeaton, Robert Zhang, Leon Liangyu Chen, Xiaokun Chen, Steven Dillmann, Saadia Gabriel, Xunyi Jiang, Anurag Kashyap, Boxuan Li, Yein Park, Minh Pham, Sujay Sanghavi, Lin Shi, Ke Sun, Yixin Wang, Zhiwei Xu, Erica Zhang, Siyan Zhao, Wanjia Zhao, Jenia Jitsev, Alex Dimakis, Benjamin Feuer, Ludwig Schmidt
By: Haichao Chen, Songchi Zhou, Zhengyun Zhao, Shikai Hu, Xianghong Jin, Hongwei Ji, Li He, Shuli Li, Yiming Qin, Xin Tan, Runfeng Shi, Yih Chung Tham, Jiaye Zhu, Ye Li, Ye Jin, Longhao Cao, Dawei Li, Honghan Wu, Hongqiu Gu, Guanqiao Li, Tudor Groza, Chunying Li, Dian Zeng, Weihong Yu, Gareth Baynam, Saumya Shekhar Jamuar, Min Shen, Shuyang Zhang, Bin Sheng, Sheng Yu, Tien Yin Wong
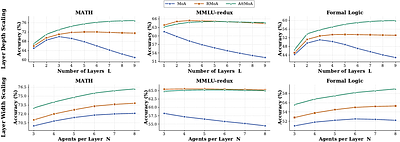
By: Heng Ping, Arijit Bhattacharjee, Peiyu Zhang, Shixuan Li, Wei Yang, Ali Jannesari, Nesreen Ahmed, Paul Bogdan
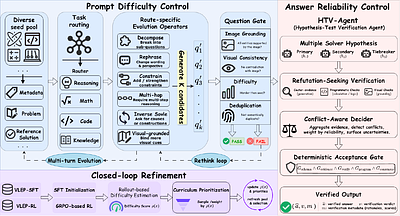
By: Haoling Li, Kai Zheng, Jie Wu, Can Xu, Qingfeng Sun, Han Hu, Yujiu Yang

By: Guangyu Jiang, Sizhe Tang, Mahdi Imani, Tian Lan