Scalable On-Hardware Training of Quantum Neural Networks and Application to Clinical Data Imputation
Scalable On-Hardware Training of Quantum Neural Networks and Application to Clinical Data Imputation
Natansh Mathur, Panagiotis Kl. Barkoutsos, Masako Yamada, Martin Roetteler, Iordanis Kerenidis
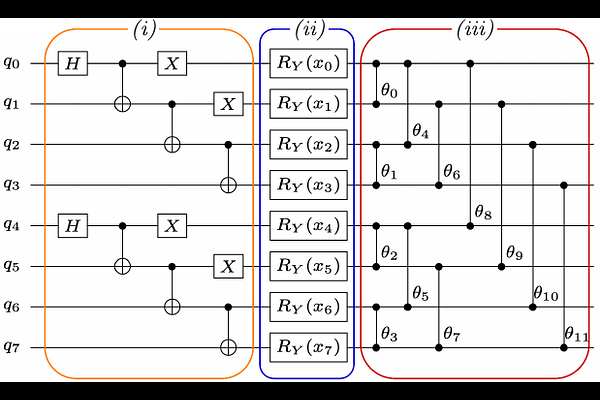
AbstractTraining quantum neural networks (QNNs) on quantum hardware is currently bottlenecked by the cost of gradient estimation: standard parameter-shift methods require a number of circuit evaluations that grows quadratically with the number of trainable parameters, making hardware-based optimisation impractical beyond small system sizes. In this work, we introduce a training framework that reduces this cost to logarithmic in the number of qubits, making gradient-based QNN optimisation feasible on near-term hardware at increasing scales. Our framework combines three co-designed ingredients: (i) a structured, subspace-preserving Butterfly circuit architecture with $O(n \log n)$ parameters and logarithmic depth; (ii) a layer-wise training strategy that confines on-hardware optimisation to one small, well-structured layer at a time; and (iii) a parallelised parameter-shift rule that exploits the commuting structure within each Butterfly layer to extract all gradients in a constant number of circuit executions. Together these reduce the number of distinct circuit evaluations per optimisation step from $O(n^2)$ to $O(\log n)$. We validate the framework on clinical data imputation using the MIMIC-III electronic health record dataset, a demanding benchmark sensitive to optimisation instability and model variance. Hybrid classical-quantum models are trained directly on IonQ Forte Enterprise trapped-ion hardware at 16 qubits without performance degradation relative to ideal or noisy simulation and via tensor-network simulation at 32 qubits, with 32-qubit inference executed on hardware. The resulting models match or exceed strong classical neural baselines in downstream patient survival prediction while exhibiting reduced variance across runs, demonstrating that the proposed framework enables practical, scalable QNN training under realistic hardware constraints.