Trust-Aware Motion Planning for Human-Robot Collaboration under Distribution Temporal Logic Specifications
Trust-Aware Motion Planning for Human-Robot Collaboration under Distribution Temporal Logic Specifications
Pian Yu, Shuyang Dong, Shili Sheng, Lu Feng, Marta Kwiatkowska
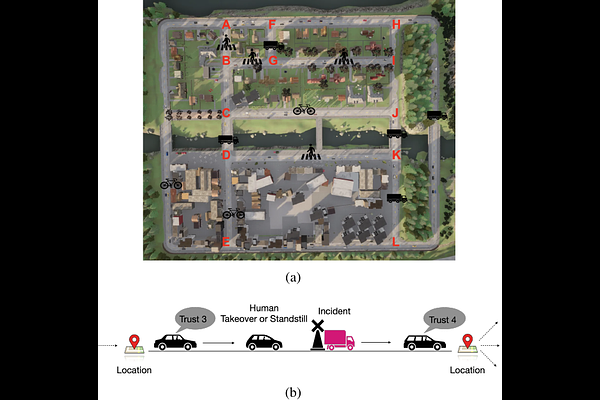
AbstractRecent work has considered trust-aware decision making for human-robot collaboration (HRC) with a focus on model learning. In this paper, we are interested in enabling the HRC system to complete complex tasks specified using temporal logic that involve human trust. Since human trust in robots is not observable, we adopt the widely used partially observable Markov decision process (POMDP) framework for modelling the interactions between humans and robots. To specify the desired behaviour, we propose to use syntactically co-safe linear distribution temporal logic (scLDTL), a logic that is defined over predicates of states as well as belief states of partially observable systems. The incorporation of belief predicates in scLDTL enhances its expressiveness while simultaneously introducing added complexity. This also presents a new challenge as the belief predicates must be evaluated over the continuous (infinite) belief space. To address this challenge, we present an algorithm for solving the optimal policy synthesis problem. First, we enhance the belief MDP (derived by reformulating the POMDP) with a probabilistic labelling function. Then a product belief MDP is constructed between the probabilistically labelled belief MDP and the automaton translation of the scLDTL formula. Finally, we show that the optimal policy can be obtained by leveraging existing point-based value iteration algorithms with essential modifications. Human subject experiments with 21 participants on a driving simulator demonstrate the effectiveness of the proposed approach.