Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Drive Anywhere: Generalizable End-to-end Autonomous Driving with Multi-modal Foundation Models
Tsun-Hsuan Wang, Alaa Maalouf, Wei Xiao, Yutong Ban, Alexander Amini, Guy Rosman, Sertac Karaman, Daniela Rus
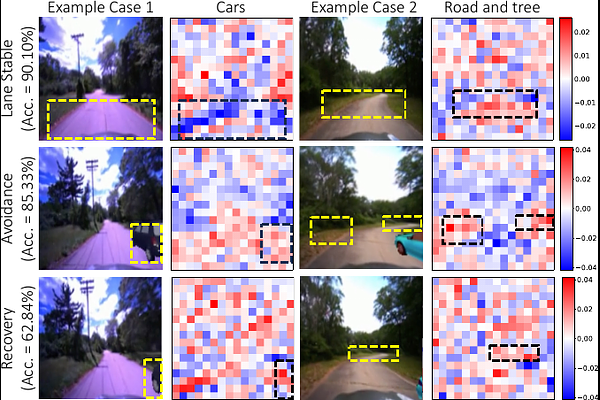
AbstractAs autonomous driving technology matures, end-to-end methodologies have emerged as a leading strategy, promising seamless integration from perception to control via deep learning. However, existing systems grapple with challenges such as unexpected open set environments and the complexity of black-box models. At the same time, the evolution of deep learning introduces larger, multimodal foundational models, offering multi-modal visual and textual understanding. In this paper, we harness these multimodal foundation models to enhance the robustness and adaptability of autonomous driving systems, enabling out-of-distribution, end-to-end, multimodal, and more explainable autonomy. Specifically, we present an approach to apply end-to-end open-set (any environment/scene) autonomous driving that is capable of providing driving decisions from representations queryable by image and text. To do so, we introduce a method to extract nuanced spatial (pixel/patch-aligned) features from transformers to enable the encapsulation of both spatial and semantic features. Our approach (i) demonstrates unparalleled results in diverse tests while achieving significantly greater robustness in out-of-distribution situations, and (ii) allows the incorporation of latent space simulation (via text) for improved training (data augmentation via text) and policy debugging. We encourage the reader to check our explainer video at https://www.youtube.com/watch?v=4n-DJf8vXxo&feature=youtu.be and to view the code and demos on our project webpage at https://drive-anywhere.github.io/.