Transcriptomic data and biomedical literature synergize in finding pharmacologic gene regulators
Transcriptomic data and biomedical literature synergize in finding pharmacologic gene regulators
Deisseroth, C. A.; Brazelton, B.; Shaik, Z.; Liu, Z.; Zoghbi, H. Y.
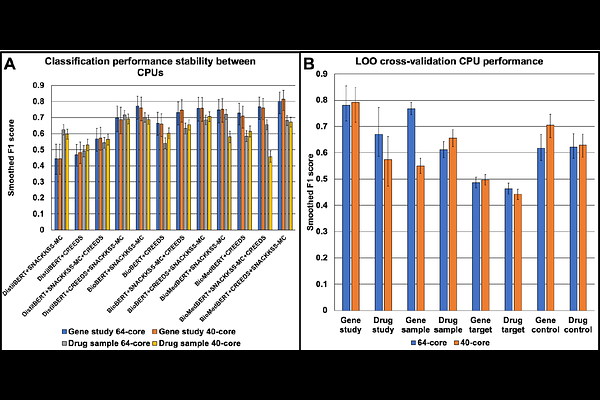
AbstractMost Mendelian disorders caused by a deficiency or excess of one gene product lack targeted therapies. Since these disorders can be modeled with a gene overexpression, knockout, or knockdown, drugs that oppose the transcriptomic effects of such perturbations may be promising therapeutic candidates. RNA-Sequencing (RNA-Seq) studies can fuel this drug-prioritization, but their labels, written in plain language, must be annotated manually. Hence, we introduce Signature-based Networks from Automatically Curated Knockout, Knockdown, and Small-molecule Studies (SNACKKSS), which automatically curates gene-disruption and drug studies from the Gene Expression Omnibus and, in partnership with uniformly computed read count datasets, feeds the labels and RNA-Seq data directly into regulatory relationship predictions. Through cross-validation, we show that SNACKKSS' predictions (specifically, from a variation called "SA4") make a unique contribution to finding protein-inhibiting compounds, even alongside existing predictors. We demonstrate the benefit of aggregating multiple predictive tools, and provide this powerful ensemble alongside SNACKKSS. Importantly, though, we advise researchers to test complex machine learning models on multiple devices. Even with code packages kept consistent, they can run deterministically within a machine, but inconsistently on different ones. Nonetheless, the downstream predictive ability was striking, and leveraging multiple sources of information, RNA-Seq data included, will vastly improve drug-repurposing screens.