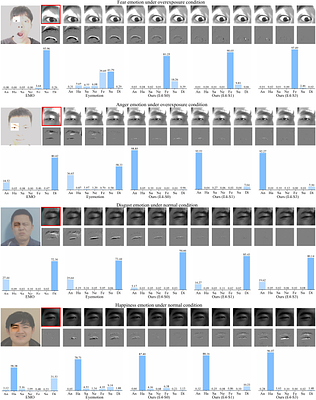
By: Haiwei Zhang, Jiqing Zhang, Bo Dong, Pieter Peers, Wenwei Wu, Xiaopeng Wei, Felix Heide, Xin Yang
We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 ... more
We introduce a wearable single-eye emotion recognition device and a real-time approach to recognizing emotions from partial observations of an emotion that is robust to changes in lighting conditions. At the heart of our method is a bio-inspired event-based camera setup and a newly designed lightweight Spiking Eye Emotion Network (SEEN). Compared to conventional cameras, event-based cameras offer a higher dynamic range (up to 140 dB vs. 80 dB) and a higher temporal resolution. Thus, the captured events can encode rich temporal cues under challenging lighting conditions. However, these events lack texture information, posing problems in decoding temporal information effectively. SEEN tackles this issue from two different perspectives. First, we adopt convolutional spiking layers to take advantage of the spiking neural network's ability to decode pertinent temporal information. Second, SEEN learns to extract essential spatial cues from corresponding intensity frames and leverages a novel weight-copy scheme to convey spatial attention to the convolutional spiking layers during training and inference. We extensively validate and demonstrate the effectiveness of our approach on a specially collected Single-eye Event-based Emotion (SEE) dataset. To the best of our knowledge, our method is the first eye-based emotion recognition method that leverages event-based cameras and spiking neural network. less

By: Javor Kalojanov, Kimball Thurston
We present a method for converting denoising neural networks from spatial into spatio-temporal ones by modifying the network architecture and loss function. We insert Robust Average blocks at arbitrary depths in the network graph. Each block performs latent space interpolation with trainable weights and works on the sequence of image representations from the preceding spatial components of the network. The temporal connections are kept live... more
We present a method for converting denoising neural networks from spatial into spatio-temporal ones by modifying the network architecture and loss function. We insert Robust Average blocks at arbitrary depths in the network graph. Each block performs latent space interpolation with trainable weights and works on the sequence of image representations from the preceding spatial components of the network. The temporal connections are kept live during training by forcing the network to predict a denoised frame from subsets of the input sequence. Using temporal coherence for denoising improves image quality and reduces temporal flickering independent of scene or image complexity. less

By: Markus Schütz, Lukas Herzberger, Michael Wimmer
About: We propose an incremental LOD generation approach for point clouds that allows us to simultaneously load points from disk, update an octree-based level-of-detail representation, and render the intermediate results in real time while additional points are still being loaded from disk. LOD construction and rendering are both implemented in CUDA and share the GPU's processing power, but each incremental update is lightweight enough to l... more
About: We propose an incremental LOD generation approach for point clouds that allows us to simultaneously load points from disk, update an octree-based level-of-detail representation, and render the intermediate results in real time while additional points are still being loaded from disk. LOD construction and rendering are both implemented in CUDA and share the GPU's processing power, but each incremental update is lightweight enough to leave enough time to maintain real-time frame rates. Background: LOD construction is typically implemented as a preprocessing step that requires users to wait before they are able to view the results in real time. This approach allows users to view intermediate results right away. Results: Our approach is able to stream points from an SSD and update the octree on the GPU at rates of up to 580 million points per second (~9.3GB/s from a PCIe 5.0 SSD) on an RTX 4090. Depending on the data set, our approach spends an average of about 1 to 2 ms to incrementally insert 1 million points into the octree, allowing us to insert several million points per frame into the LOD structure and render the intermediate results within the same frame. Discussion/Limitations: We aim to provide near-instant, real-time visualization of large data sets without preprocessing. Out-of-core processing of arbitrarily large data sets and color-filtering for higher-quality LODs are subject to future work. less
By: Zhaoyang Wang, Stefan Wesner, Stefan Zellmann
Rendering large adaptive mesh refinement (AMR) data in real-time in virtual reality (VR) environments is a complex challenge that demands sophisticated techniques and tools. The proposed solution harnesses the ExaBrick framework and integrates it as a plugin in COVISE, a robust visualization system equipped with the VR-centric OpenCOVER render module. This setup enables direct navigation and interaction within the rendered volume in a VR en... more
Rendering large adaptive mesh refinement (AMR) data in real-time in virtual reality (VR) environments is a complex challenge that demands sophisticated techniques and tools. The proposed solution harnesses the ExaBrick framework and integrates it as a plugin in COVISE, a robust visualization system equipped with the VR-centric OpenCOVER render module. This setup enables direct navigation and interaction within the rendered volume in a VR environment. The user interface incorporates rendering options and functions, ensuring a smooth and interactive experience. We show that high-quality volume rendering of AMR data in VR environments at interactive rates is possible using GPUs. less
By: Miša Korać, Corentin Salaün, Iliyan Georgiev, Pascal Grittmann, Philipp Slusallek, Karol Myszkowski, Gurprit Singh
Independently estimating pixel values in Monte Carlo rendering results in a perceptually sub-optimal white-noise distribution of error in image space. Recent works have shown that perceptual fidelity can be improved significantly by distributing pixel error as blue noise instead. Most such works have focused on static images, ignoring the temporal perceptual effects of animation display. We extend prior formulations to simultaneously consid... more
Independently estimating pixel values in Monte Carlo rendering results in a perceptually sub-optimal white-noise distribution of error in image space. Recent works have shown that perceptual fidelity can be improved significantly by distributing pixel error as blue noise instead. Most such works have focused on static images, ignoring the temporal perceptual effects of animation display. We extend prior formulations to simultaneously consider the spatial and temporal domains, and perform an analysis to motivate a perceptually better spatio-temporal error distribution. We then propose a practical error optimization algorithm for spatio-temporal rendering and demonstrate its effectiveness in various configurations. less
By: Lukas Lipp, David Hahn, Pierre Ecormier-Nocca, Florian Rist, Michael Wimmer
Controlling light is a central element when composing a scene, enabling artistic expression, as well as the design of comfortable living spaces. In contrast to previous camera-based inverse rendering approaches, we introduce a novel method for interactive, view-independent differentiable global illumination. Our method first performs a forward light-tracing pass, starting from the light sources and storing the resulting radiance field on th... more
Controlling light is a central element when composing a scene, enabling artistic expression, as well as the design of comfortable living spaces. In contrast to previous camera-based inverse rendering approaches, we introduce a novel method for interactive, view-independent differentiable global illumination. Our method first performs a forward light-tracing pass, starting from the light sources and storing the resulting radiance field on the scene geometry, representing specular highlights via hemi-spherical harmonics. We then evaluate an objective function on the entire radiance data and propagate derivatives back to the lighting parameters by formulating a novel, analytical adjoint light-tracing step. Our method builds on GPU ray tracing, which allows us to optimize all lighting parameters at interactive rates, even for complex geometry. Instead of specifying optimization targets as view-specific images, our method allows us to optimize the lighting of an entire scene to match either baked illumination (e.g., lightmaps), regulatory lighting requirements for work spaces, or artistic sketches drawn directly on the geometry. This approach provides a more direct and intuitive user experience for designers. We visualize our adjoint gradients and compare them to image-based state-of-the-art differentiable rendering methods. We also compare the convergence behavior of various optimization algorithms when using our gradient data vs. image-based differentiable rendering methods. Qualitative comparisons with real-world scenes underline the practical applicability of our method. less