
By: Mengxuan Zhang, Xinjie Zhou, Lei Li, Ziyi Liu, Goce Trajcevski, Yan Huang, Xiaofang Zhou
Graph partitioning is a common solution to scale up the graph algorithms, and shortest path (SP) computation is one of them. However, the existing solutions typically have a fixed partition method with a fixed path index and fixed partition structure, so it is unclear how the partition method and path index influence the pathfinding performance. Moreover, few studies have explored the index maintenance of partitioned SP (PSP) on dynamic gra... more
Graph partitioning is a common solution to scale up the graph algorithms, and shortest path (SP) computation is one of them. However, the existing solutions typically have a fixed partition method with a fixed path index and fixed partition structure, so it is unclear how the partition method and path index influence the pathfinding performance. Moreover, few studies have explored the index maintenance of partitioned SP (PSP) on dynamic graphs. To provide a deeper insight into the dynamic PSP indexes, we systematically deliberate on the existing works and propose a universal scheme to analyze this problem theoretically. Specifically, we first propose two novel partitioned index strategies and one optimization to improve index construction, query answering, or index maintenance of PSP index. Then we propose a path-oriented graph partitioning classification criteria for easier partition method selection. After that, we re-couple the dimensions in our scheme (partitioned index strategy, path index, and partition structure) to propose five new partitioned SP indexes that are more efficient either in the query or update on different networks. Finally, we demonstrate the effectiveness of our new indexes by comparing them with state-of-the-art PSP indexes through comprehensive evaluations. less
Spatio-temporal flow patterns
0upvotes
By: Chrysanthi Kosyfaki, Nikos Mamoulis, Reynold Cheng, Ben Kao
Transportation companies and organizations routinely collect huge volumes of passenger transportation data. By aggregating these data (e.g., counting the number of passengers going from a place to another in every 30 minute interval), it becomes possible to analyze the movement behavior of passengers in a metropolitan area. In this paper, we study the problem of finding important trends in passenger movements at varying granularities, which... more
Transportation companies and organizations routinely collect huge volumes of passenger transportation data. By aggregating these data (e.g., counting the number of passengers going from a place to another in every 30 minute interval), it becomes possible to analyze the movement behavior of passengers in a metropolitan area. In this paper, we study the problem of finding important trends in passenger movements at varying granularities, which is useful in a wide range of applications such as target marketing, scheduling, and travel intent prediction. Specifically, we study the extraction of movement patterns between regions that have significant flow. The huge number of possible patterns render their detection computationally hard. We propose algorithms that greatly reduce the search space and the computational cost of pattern detection. We study variants of patterns that could be useful to different problem instances, such as constrained patterns and top-k ranked patterns. less
By: Sachith Pai, Michael Mathioudakis, Yanhao Wang
In this paper, a learned and workload-aware variant of a Z-index, which jointly optimizes storage layout and search structures, as a viable solution for the above challenges of spatial indexing. Specifically, we first formulate a cost function to measure the performance of a Z-index on a dataset for a range-query workload. Then, we optimize the Z-index structure by minimizing the cost function through adaptive partitioning and ordering for ... more
In this paper, a learned and workload-aware variant of a Z-index, which jointly optimizes storage layout and search structures, as a viable solution for the above challenges of spatial indexing. Specifically, we first formulate a cost function to measure the performance of a Z-index on a dataset for a range-query workload. Then, we optimize the Z-index structure by minimizing the cost function through adaptive partitioning and ordering for index construction. Moreover, we design a novel page-skipping mechanism to improve its query performance by reducing access to irrelevant data pages. Our extensive experiments show that our index improves range query time by 40% on average over the baselines, while always performing better or comparably to state-of-the-art spatial indexes. Additionally, our index maintains good point query performance while providing favourable construction time and index size tradeoffs. less
By: Zhiyi Yao, Bowen Ding, Qianlan Bai, Yuedong Xu
Data silos create barriers in accessing and utilizing data dispersed over networks. Directly sharing data easily suffers from the long downloading time, the single point failure and the untraceable data usage. In this paper, we present Minerva, a peer-to-peer cross-cluster data query system based on InterPlanetary File System (IPFS). Minerva makes use of the distributed Hash table (DHT) lookup to pinpoint the locations that store content ch... more
Data silos create barriers in accessing and utilizing data dispersed over networks. Directly sharing data easily suffers from the long downloading time, the single point failure and the untraceable data usage. In this paper, we present Minerva, a peer-to-peer cross-cluster data query system based on InterPlanetary File System (IPFS). Minerva makes use of the distributed Hash table (DHT) lookup to pinpoint the locations that store content chunks. We theoretically model the DHT query delay and introduce the fat Merkle tree structure as well as the DHT caching to reduce it. We design the query plan for read and write operations on top of Apache Drill that enables the collaborative query with decentralized workers. We conduct comprehensive experiments on Minerva, and the results show that Minerva achieves up to $2.08 \times$ query performance acceleration compared to the original IPFS data query, and could complete data analysis queries on the Internet-like environments within an average latency of $0.615$ second. With collaborative query, Minerva could perform up to $1.39 \times$ performance acceleration than centralized query with raw data shipment. less
By: Mahdi Esmailoghli, Christoph Schnell, Renée J. Miller, Ziawasch Abedjan
Data discovery is an iterative and incremental process that necessitates the execution of multiple data discovery queries to identify the desired tables from large and diverse data lakes. Current methodologies concentrate on single discovery tasks such as join, correlation, or union discovery. However, in practice, a series of these approaches and their corresponding index structures are necessary to enable the user to discover the desired ... more
Data discovery is an iterative and incremental process that necessitates the execution of multiple data discovery queries to identify the desired tables from large and diverse data lakes. Current methodologies concentrate on single discovery tasks such as join, correlation, or union discovery. However, in practice, a series of these approaches and their corresponding index structures are necessary to enable the user to discover the desired tables. This paper presents BLEND, a comprehensive data discovery system that empowers users to develop ad-hoc discovery tasks without the need to develop new algorithms or build a new index structure. To achieve this goal, we introduce a general index structure capable of addressing multiple discovery queries. We develop a set of lower-level operators that serve as the fundamental building blocks for more complex and sophisticated user tasks. These operators are highly efficient and enable end-to-end efficiency. To enhance the execution of the discovery pipeline, we rewrite the search queries into optimized SQL statements to push the data operators down to the database. We demonstrate that our holistic system is able to achieve comparable effectiveness and runtime efficiency to the individual state-of-the-art approaches specifically designed for a single task. less
By: Youxi Wu, Yufei Meng, Yan Li, Lei Guo, Xingquan Zhu, Philippe Fournier-Viger, Xindong Wu
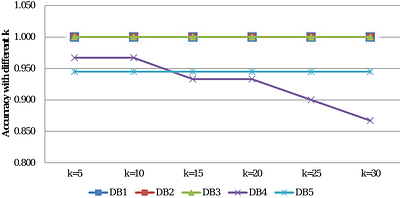
Recently, order-preserving pattern (OPP) mining, a new sequential pattern mining method, has been proposed to mine frequent relative orders in a time series. Although frequent relative orders can be used as features to classify a time series, the mined patterns do not reflect the differences between two classes of time series well. To effectively discover the differences between time series, this paper addresses the top-k contrast OPP (COPP... more
Recently, order-preserving pattern (OPP) mining, a new sequential pattern mining method, has been proposed to mine frequent relative orders in a time series. Although frequent relative orders can be used as features to classify a time series, the mined patterns do not reflect the differences between two classes of time series well. To effectively discover the differences between time series, this paper addresses the top-k contrast OPP (COPP) mining and proposes a COPP-Miner algorithm to discover the top-k contrast patterns as features for time series classification, avoiding the problem of improper parameter setting. COPP-Miner is composed of three parts: extreme point extraction to reduce the length of the original time series, forward mining, and reverse mining to discover COPPs. Forward mining contains three steps: group pattern fusion strategy to generate candidate patterns, the support rate calculation method to efficiently calculate the support of a pattern, and two pruning strategies to further prune candidate patterns. Reverse mining uses one pruning strategy to prune candidate patterns and consists of applying the same process as forward mining. Experimental results validate the efficiency of the proposed algorithm and show that top-k COPPs can be used as features to obtain a better classification performance. less
By: Miika Hannula
Conditional independence plays a foundational role in database theory, probability theory, information theory, and graphical models. In databases, conditional independence appears in database normalization and is known as the (embedded) multivalued dependency. Many properties of conditional independence are shared across various domains, and to some extent these commonalities can be studied through a measure-theoretic approach. The present ... more
Conditional independence plays a foundational role in database theory, probability theory, information theory, and graphical models. In databases, conditional independence appears in database normalization and is known as the (embedded) multivalued dependency. Many properties of conditional independence are shared across various domains, and to some extent these commonalities can be studied through a measure-theoretic approach. The present paper proposes an alternative approach via semiring relations, defined by extending database relations with tuple annotations from some commutative semiring. Integrating various interpretations of conditional independence in this context, we investigate how the choice of the underlying semiring impacts the corresponding axiomatic and decomposition properties. We specifically identify positivity and multiplicative cancellativity as the key semiring properties that enable extending results from the relational context to the broader semiring framework. Additionally, we explore the relationships between different conditional independence notions through model theory, and consider how methods to test logical consequence and validity generalize from database theory and information theory to semiring relations. less
Optimizing substructure search: a novel approach for efficient querying in large chemical databases
0upvotes
By: Vsevolod Vaskin, Dmitri Jakovlev, Fedor Bakharev
Substructure search in chemical compound databases is a fundamental task in cheminformatics with critical implications for fields such as drug discovery, materials science, and toxicology. However, the increasing size and complexity of chemical databases have rendered traditional search algorithms ineffective, exacerbating the need for scalable solutions. We introduce a novel approach to enhance the efficiency of substructure search, moving... more
Substructure search in chemical compound databases is a fundamental task in cheminformatics with critical implications for fields such as drug discovery, materials science, and toxicology. However, the increasing size and complexity of chemical databases have rendered traditional search algorithms ineffective, exacerbating the need for scalable solutions. We introduce a novel approach to enhance the efficiency of substructure search, moving beyond the traditional full-enumeration methods. Our strategy employs a unique index structure: a tree that segments the molecular data set into clusters based on the presence or absence of certain features. This innovative indexing mechanism is inspired by the binary Ball-Tree concept and demonstrates superior performance over exhaustive search methods, leading to significant acceleration in the initial filtering process. Comparative analysis with the existing Bingo algorithm reveals the efficiency and versatility of our approach. Although the current implementation does not affect the verification stage, it has the potential to reduce false positive rates. Our method offers a promising avenue for future research, meeting the growing demand for fast and accurate substructure search in increasingly large chemical databases. less
Rel2Graph: Automated Mapping From Relational Databases to a Unified Property Knowledge Graph
0upvotes
By: Ziyu Zhao, Wei Liu, Tim French, Michael Stewart
Although a few approaches are proposed to convert relational databases to graphs, there is a genuine lack of systematic evaluation across a wider spectrum of databases. Recognising the important issue of query mapping, this paper proposes an approach Rel2Graph, an automatic knowledge graph construction (KGC) approach from an arbitrary number of relational databases. Our approach also supports the mapping of conjunctive SQL queries into patt... more
Although a few approaches are proposed to convert relational databases to graphs, there is a genuine lack of systematic evaluation across a wider spectrum of databases. Recognising the important issue of query mapping, this paper proposes an approach Rel2Graph, an automatic knowledge graph construction (KGC) approach from an arbitrary number of relational databases. Our approach also supports the mapping of conjunctive SQL queries into pattern-based NoSQL queries. We evaluate our proposed approach on two widely used relational database-oriented datasets: Spider and KaggleDBQA benchmarks for semantic parsing. We employ the execution accuracy (EA) metric to quantify the proportion of results by executing the NoSQL queries on the property knowledge graph we construct that aligns with the results of SQL queries performed on relational databases. Consequently, the counterpart property knowledge graph of benchmarks with high accuracy and integrity can be ensured. The code and data will be publicly available. The code and data are available at github\footnote{https://github.com/nlp-tlp/Rel2Graph}. less
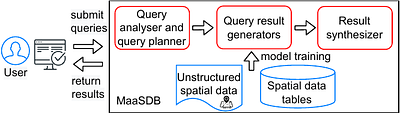
By: Jianzhong Qi, Zuqing Li, Egemen Tanin
Large language models (LLMs) are advancing rapidly. Such models have demonstrated strong capabilities in learning from large-scale (unstructured) text data and answering user queries. Users do not need to be experts in structured query languages to interact with systems built upon such models. This provides great opportunities to reduce the barrier of information retrieval for the general public. By introducing LLMs into spatial data manage... more
Large language models (LLMs) are advancing rapidly. Such models have demonstrated strong capabilities in learning from large-scale (unstructured) text data and answering user queries. Users do not need to be experts in structured query languages to interact with systems built upon such models. This provides great opportunities to reduce the barrier of information retrieval for the general public. By introducing LLMs into spatial data management, we envisage an LLM-based spatial database system to learn from both structured and unstructured spatial data. Such a system will offer seamless access to spatial knowledge for the users, thus benefiting individuals, business, and government policy makers alike. less