Self-supervised Scene Text Segmentation with Object-centric Layered Representations Augmented by Text Regions
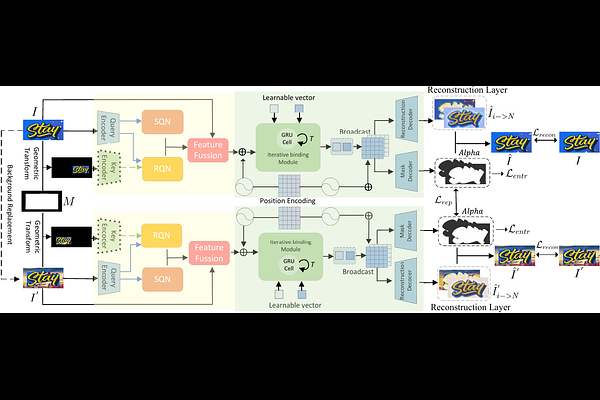
Self-supervised Scene Text Segmentation with Object-centric Layered Representations Augmented by Text Regions
Yibo Wang, Yunhu Ye, Yuanpeng Mao, Yanwei Yu, Yuanping Song
AbstractText segmentation tasks have a very wide range of application values, such as image editing, style transfer, watermark removal, etc.However, existing public datasets are of poor quality of pixel-level labels that have been shown to be notoriously costly to acquire, both in terms of money and time. At the same time, when pretraining is performed on synthetic datasets, the data distribution of the synthetic datasets is far from the data distribution in the real scene. These all pose a huge challenge to the current pixel-level text segmentation algorithms.To alleviate the above problems, we propose a self-supervised scene text segmentation algorithm with layered decoupling of representations derived from the object-centric manner to segment images into texts and background. In our method, we propose two novel designs which include Region Query Module and Representation Consistency Constraints adapting to the unique properties of text as complements to Auto Encoder, which improves the network's sensitivity to texts.For this unique design, we treat the polygon-level masks predicted by the text localization model as extra input information, and neither utilize any pixel-level mask annotations for training stage nor pretrain on synthetic datasets.Extensive experiments show the effectiveness of the method proposed. On several public scene text datasets, our method outperforms the state-of-the-art unsupervised segmentation algorithms.