Bilevel Scheduled Sampling for Dialogue Generation
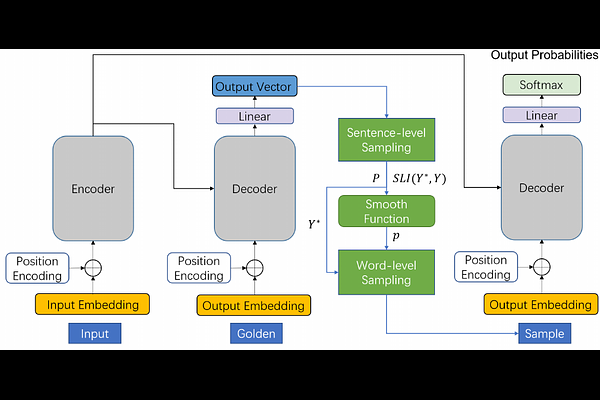
Bilevel Scheduled Sampling for Dialogue Generation
Jiawen Liu, Kan Li
AbstractExposure bias poses a common challenge in numerous natural language processing tasks, particularly in the dialog generation. In response to this issue, researchers have devised various techniques, among which scheduled sampling has proven to be an effective method for mitigating exposure bias. However, the existing state-of-the-art scheduled sampling methods solely consider the current sampling words' quality for threshold truncation sampling, which overlooks the importance of sentence-level information and the method of threshold truncation warrants further discussion. In this paper, we propose a bilevel scheduled sampling model that takes the sentence-level information into account and incorporates it with word-level quality. To enhance sampling diversity and improve the model's adaptability, we propose a smooth function that maps the combined result of sentence-level and word-level information to an appropriate range, and employ probabilistic sampling based on the mapped values instead of threshold truncation. Experiments conducted on the DailyDialog and PersonaChat datasets demonstrate the effectiveness of our proposed methods, which significantly alleviate the exposure bias problem and outperform state-of-the-art scheduled sampling methods.