Learning to Behave Like Clean Speech: Dual-Branch Knowledge Distillation for Noise-Robust Fake Audio Detection
Learning to Behave Like Clean Speech: Dual-Branch Knowledge Distillation for Noise-Robust Fake Audio Detection
Cunhang Fan, Mingming Ding, Jianhua Tao, Ruibo Fu, Jiangyan Yi, Zhengqi Wen, Zhao Lv
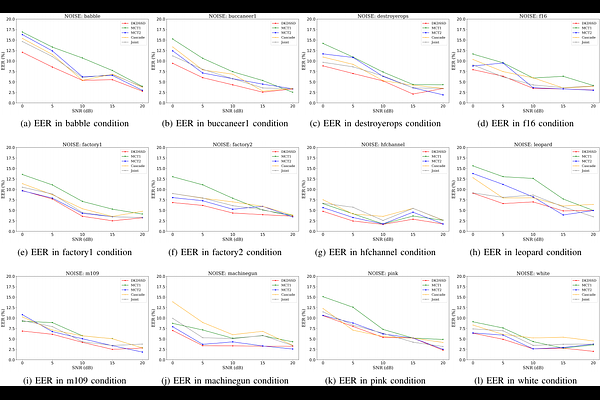
AbstractMost research in fake audio detection (FAD) focuses on improving performance on standard noise-free datasets. However, in actual situations, there is usually noise interference, which will cause significant performance degradation in FAD systems. To improve the noise robustness, we propose a dual-branch knowledge distillation fake audio detection (DKDFAD) method. Specifically, a parallel data flow of the clean teacher branch and the noisy student branch is designed, and interactive fusion and response-based teacher-student paradigms are proposed to guide the training of noisy data from the data distribution and decision-making perspectives. In the noise branch, speech enhancement is first introduced for denoising, which reduces the interference of strong noise. The proposed interactive fusion combines denoising features and noise features to reduce the impact of speech distortion and seek consistency with the data distribution of clean branch. The teacher-student paradigm maps the student's decision space to the teacher's decision space, making noisy speech behave as clean. In addition, a joint training method is used to optimize the two branches to achieve global optimality. Experimental results based on multiple datasets show that the proposed method performs well in noisy environments and maintains performance in cross-dataset experiments.