Sparse Linear Concept Discovery Models
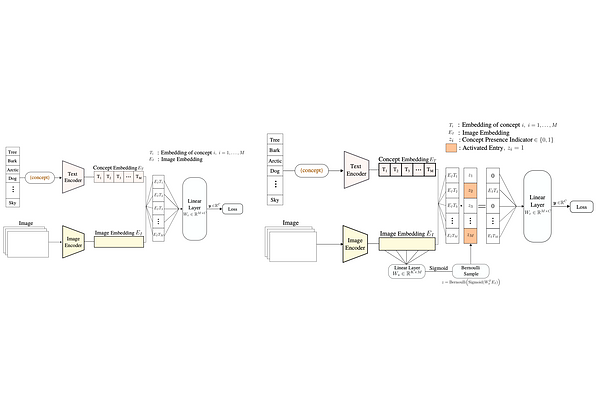
Sparse Linear Concept Discovery Models
Konstantinos P. Panousis, Dino Ienco, Diego Marcos
AbstractThe recent mass adoption of DNNs, even in safety-critical scenarios, has shifted the focus of the research community towards the creation of inherently intrepretable models. Concept Bottleneck Models (CBMs) constitute a popular approach where hidden layers are tied to human understandable concepts allowing for investigation and correction of the network's decisions. However, CBMs usually suffer from: (i) performance degradation and (ii) lower interpretability than intended due to the sheer amount of concepts contributing to each decision. In this work, we propose a simple yet highly intuitive interpretable framework based on Contrastive Language Image models and a single sparse linear layer. In stark contrast to related approaches, the sparsity in our framework is achieved via principled Bayesian arguments by inferring concept presence via a data-driven Bernoulli distribution. As we experimentally show, our framework not only outperforms recent CBM approaches accuracy-wise, but it also yields high per example concept sparsity, facilitating the individual investigation of the emerging concepts.