Can Transformer and GNN Help Each Other?
Can Transformer and GNN Help Each Other?
Peiyan Zhang, Yuchen Yan, Chaozhuo Li, Senzhang Wang, Xing Xie, Sunghun Kim
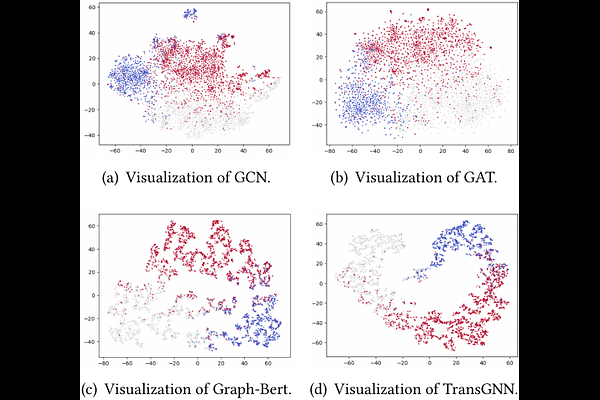
AbstractAlthough Transformer has achieved great success in natural language process and computer vision, it has difficulty generalizing to medium and large-scale graph data for two important reasons: (i) High complexity. (ii) Failing to capture the complex and entangled structure information. In graph representation learning, Graph Neural Networks(GNNs) can fuse the graph structure and node attributes but have limited receptive fields. Therefore, we question whether can we combine Transformers and GNNs to help each other. In this paper, we propose a new model named TransGNN where the Transformer layer and GNN layer are used alternately to improve each other. Specifically, to expand the receptive field and disentangle the information aggregation from edges, we propose using Transformer to aggregate more relevant nodes' information to improve the message passing of GNNs. Besides, to capture the graph structure information, we utilize positional encoding and make use of the GNN layer to fuse the structure into node attributes, which improves the Transformer in graph data. We also propose to sample the most relevant nodes for Transformer and two efficient samples update strategies to lower the complexity. At last, we theoretically prove that TransGNN is more expressive than GNNs only with extra linear complexity. The experiments on eight datasets corroborate the effectiveness of TransGNN on node and graph classification tasks.