XIMAGENET-12: An Explainable AI Benchmark Dataset for Model Robustness Evaluation
XIMAGENET-12: An Explainable AI Benchmark Dataset for Model Robustness Evaluation
Qiang Li, Dan Zhang, Shengzhao Lei, Xun Zhao, Shuyan Li, Porawit Kamnoedboon, WeiWei Li
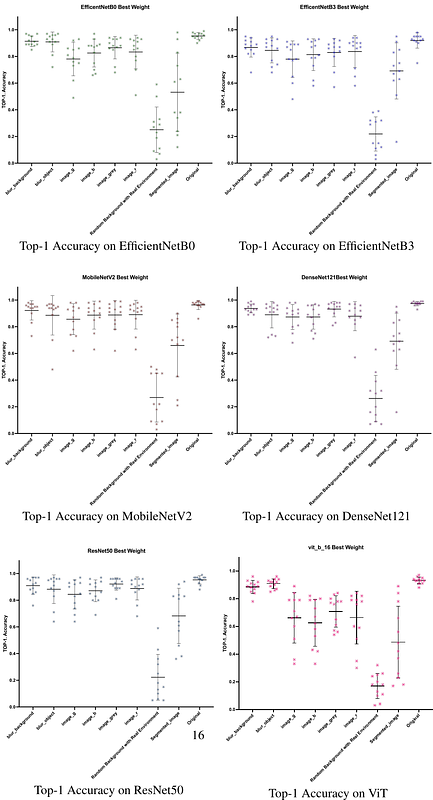
AbstractThe lack of standardized robustness metrics and the widespread reliance on numerous unrelated benchmark datasets for testing have created a gap between academically validated robust models and their often problematic practical adoption. To address this, we introduce XIMAGENET-12, an explainable benchmark dataset with over 200K images and 15,600 manual semantic annotations. Covering 12 categories from ImageNet to represent objects commonly encountered in practical life and simulating six diverse scenarios, including overexposure, blurring, color changing, etc., we further propose a novel robustness criterion that extends beyond model generation ability assessment. This benchmark dataset, along with related code, is available at https://sites.google.com/view/ximagenet-12/home. Researchers and practitioners can leverage this resource to evaluate the robustness of their visual models under challenging conditions and ultimately benefit from the demands of practical computer vision systems.