SciMDR: Benchmarking and Advancing Scientific Multimodal Document Reasoning
SciMDR: Benchmarking and Advancing Scientific Multimodal Document Reasoning
Ziyu Chen, Yilun Zhao, Chengye Wang, Rilyn Han, Manasi Patwardhan, Arman Cohan
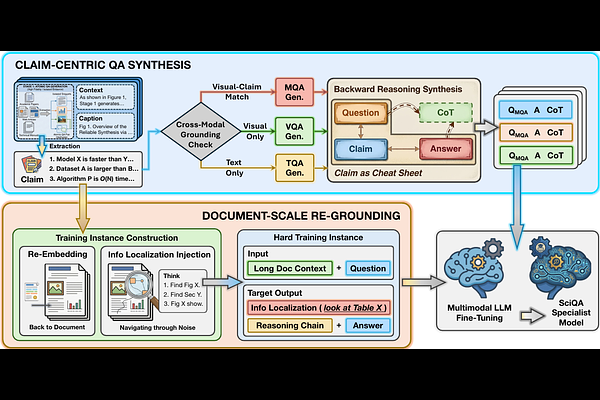
AbstractConstructing scientific multimodal document reasoning datasets for foundation model training involves an inherent trade-off among scale, faithfulness, and realism. To address this challenge, we introduce the synthesize-and-reground framework, a two-stage pipeline comprising: (1) Claim-Centric QA Synthesis, which generates faithful, isolated QA pairs and reasoning on focused segments, and (2) Document-Scale Regrounding, which programmatically re-embeds these pairs into full-document tasks to ensure realistic complexity. Using this framework, we construct SciMDR, a large-scale training dataset for cross-modal comprehension, comprising 300K QA pairs with explicit reasoning chains across 20K scientific papers. We further construct SciMDR-Eval, an expert-annotated benchmark to evaluate multimodal comprehension within full-length scientific workflows. Experiments demonstrate that models fine-tuned on SciMDR achieve significant improvements across multiple scientific QA benchmarks, particularly in those tasks requiring complex document-level reasoning.