Anomaly detection with semi-supervised classification based on risk estimators
Anomaly detection with semi-supervised classification based on risk estimators
Le Thi Khanh Hien, Sukanya Patra, Souhaib Ben Taieb
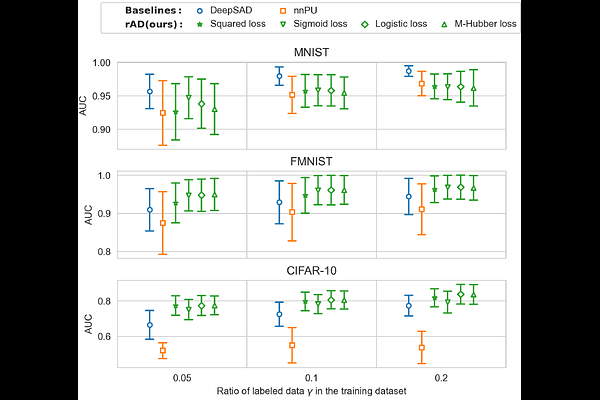
AbstractA significant limitation of one-class classification anomaly detection methods is their reliance on the assumption that unlabeled training data only contains normal instances. To overcome this impractical assumption, we propose two novel classification-based anomaly detection methods. Firstly, we introduce a semi-supervised shallow anomaly detection method based on an unbiased risk estimator. Secondly, we present a semi-supervised deep anomaly detection method utilizing a nonnegative (biased) risk estimator. We establish estimation error bounds and excess risk bounds for both risk minimizers. Additionally, we propose techniques to select appropriate regularization parameters that ensure the nonnegativity of the empirical risk in the shallow model under specific loss functions. Our extensive experiments provide strong evidence of the effectiveness of the risk-based anomaly detection methods.